A retrieval-augmented generation (RAG) app makes two very different kinds of model call: embeddings (to index documents and embed queries) and chat completions (to generate the answer from retrieved context). Teams often wire these to two different providers with two SDKs, two keys, and two billing surfaces — and then can't see the combined cost of answering a single question. A gateway collapses both behind one key, which turns out to matter more than it sounds.
The two halves of RAG
INDEX TIME QUERY TIME
docs → embeddings → vector DB query → embeddings → vector DB → top-k
│
retrieved context + query
│
chat completion → answerEmbeddings run constantly at index time and on every query; chat runs once per answer but is far more expensive per call. Both are model calls; both cost money; both can fail. Yet most RAG stacks treat them as unrelated integrations.
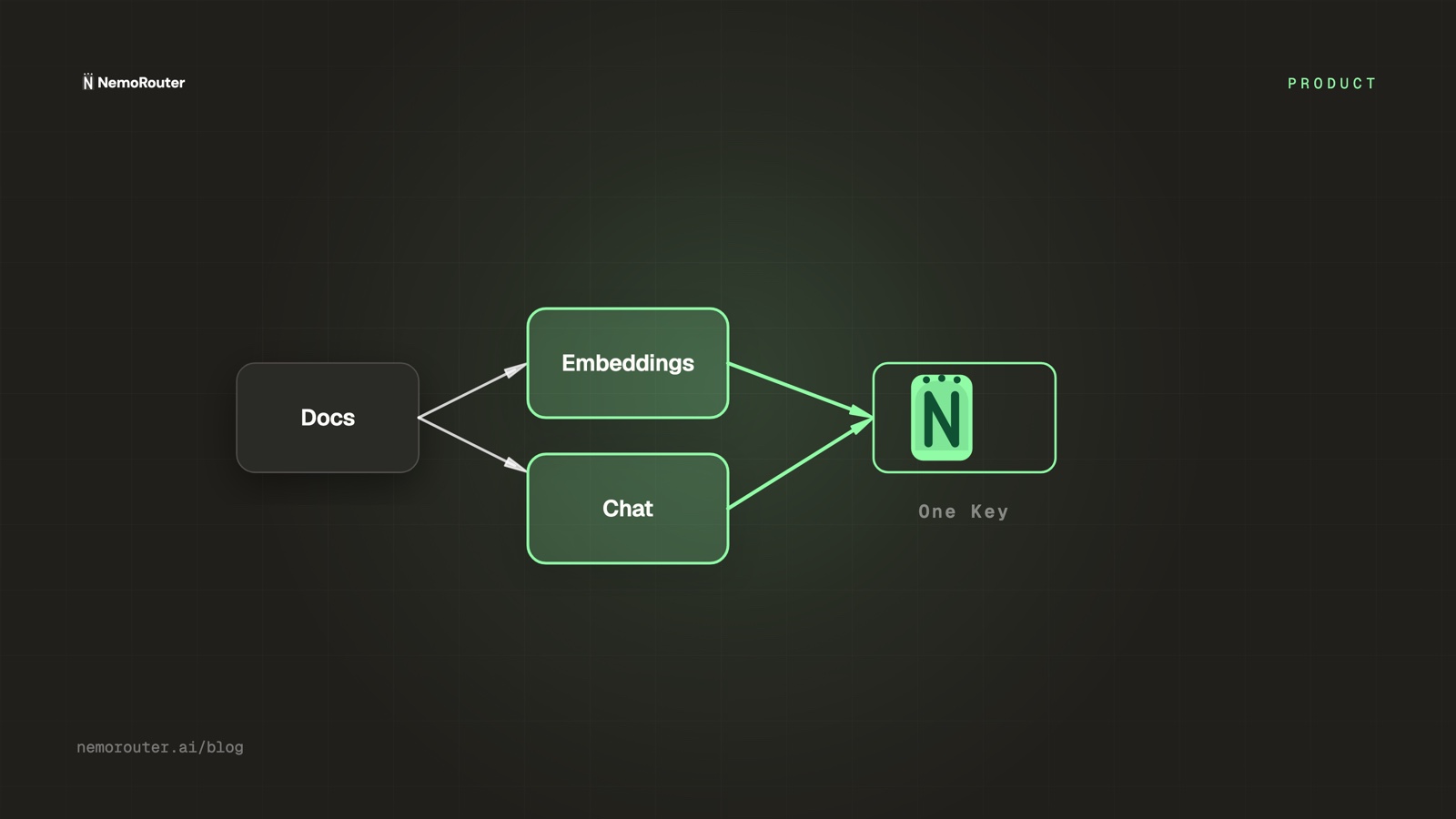
One key for both call types
Through a gateway, embeddings and chat are the same OpenAI-compatible surface, one base URL, one virtual key:
# index/query: embeddings
emb = client.embeddings.create(model="text-embedding-3-large", input=chunks)
# answer: chat, same client, same key
ans = client.chat.completions.create(model="claude-sonnet-4-6", messages=[...])One key, one bill, one place to manage both. Your retrieval layer and your generation layer stop being separate vendor relationships.
Why unifying them pays off
The win isn't just fewer SDKs — it's that cross-cutting concerns now span both halves of RAG:
- Combined cost per answer. Tag the embedding and chat calls for a query with the same
feature:rag(andcustomer:) tag, and you can sum what it truly costs to answer one question — embeddings included. Most teams only ever see the chat cost and undercount. - One budget over both. A budget cap covers your whole RAG spend, not just generation. Index-time embedding bursts (re-indexing a big corpus) are caught by the same ceiling.
- Fallback on both. An embeddings provider outage is as fatal to RAG as a chat outage — no embeddings, no retrieval. Fallback chains keep both halves available.
Re-indexing is a budget event
The classic RAG cost surprise is a full re-index: embedding a large corpus in a burst can dwarf a day of query traffic. Because the gateway meters embeddings too, that burst hits your budget and alerts — instead of showing up as a mystery line on the bill. Cap embedding spend like you cap chat.
Cost-tune each half independently
Unifying the calls also lets you optimize them separately with the same tools. Embeddings and chat have different cost/quality frontiers, so route each by need: a cheaper embedding model may be fine for retrieval quality while you keep a strong chat model for generation — or vice versa. A/B test an embedding-model swap against retrieval quality before committing, the same way you'd test a chat-model change. Two knobs, one control plane.
The takeaway
RAG is two model workloads pretending to be one app, and treating them as separate integrations hides your real cost and doubles your failure surface. Put embeddings and chat behind one gateway key and you get the combined cost per answer, one budget across index- and query-time, fallback on both halves, and independent cost-tuning of each — the whole retrieval-to-answer path under one control plane. See the models and docs to wire it up.