You want to know whether a cheaper model is good enough, or whether a new prompt actually improves quality. So you split traffic 50/50 and compare. If that split is random per request, your experiment is quietly broken: the same user bounces between variants mid-session, your metrics are noisy, and you can't reproduce a result. Deterministic A/B testing fixes this by making the split a stable function of who is calling, not a coin flip on each call.
Why random per-request splitting fails
Imagine an experiment comparing Model A and Model B at 50/50, assigned randomly on every request. A single user in one session might hit A, then B, then A again. Three problems follow:
- Inconsistent UX — the user experiences two different models in one conversation; response style and quality visibly flip.
- Confounded metrics — you can't attribute a satisfaction signal to a variant when the user saw both.
- Unrepeatable — re-run the experiment and a different random draw gives a different result. There's nothing to reproduce.
Random per request maximizes noise. What you want is random assignment, stable thereafter.
Deterministic assignment via hashing
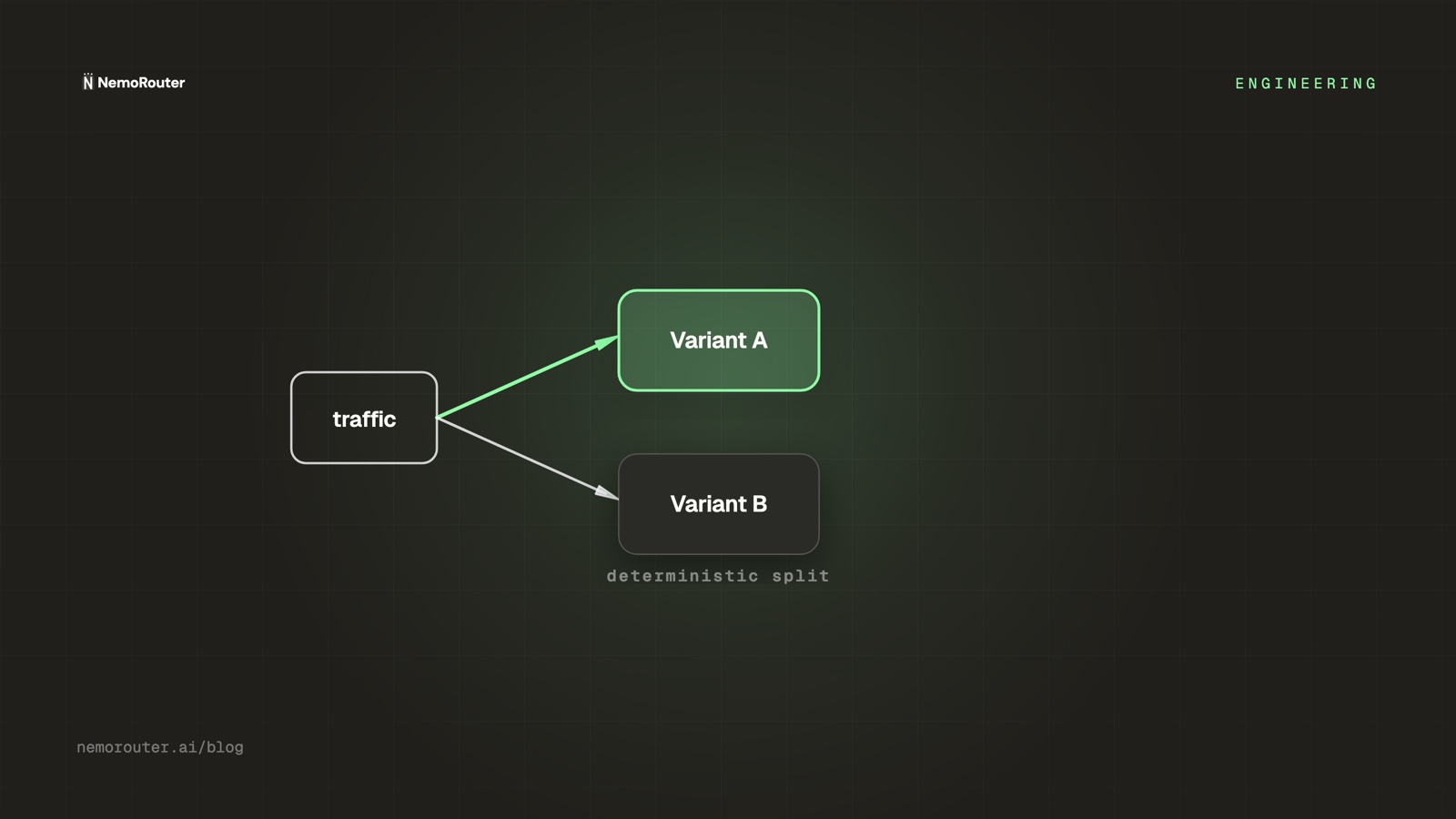
The fix is to derive the variant from a hash of a stable key (user id, session, or org) plus the experiment id — not from a random number:
bucket = hash(experiment_id + user_id) % 100
variant = bucket < 50 ? "A" : "B"Because hash(experiment_id + user_id) is deterministic, a given user always lands in the same bucket for the life of the experiment. The assignment is still uniformly distributed across users (a good hash spreads them evenly), but stable for each one. Same user, same variant, every request — until you change the experiment.
Why include the experiment id in the hash
Hashing the user id alone would put the same users in "group A" for every experiment forever — your variant-A cohort becomes a fixed set of people, and their quirks bias every test. Mixing the experiment id in re-shuffles the cohort per experiment, so each test gets an independent, unbiased split.
What you can A/B test
The same deterministic seam handles several kinds of comparison:
| Test | Variant A | Variant B | You learn |
|---|---|---|---|
| Model swap | flagship | cheaper model | Is cheaper good enough? |
| Prompt change | current prompt | revised prompt | Does the rewrite help? |
| Parameter | temp 0.7 | temp 0.3 | Does determinism improve quality? |
| Provider | provider X | provider Y | Same model, who serves it better? |
Each runs through the gateway, so the split happens centrally and your application code doesn't branch — it asks for the experiment's logical model and gets the variant the user is assigned to.
A/B tests are not request-overridable
A caller cannot ask to skip the experiment or force a variant. If they could, your sample would be self-selected and your results meaningless — and a client could dodge the cheaper variant, defeating the test. Assignment is the gateway's decision, derived deterministically, period. (This is the same principle as rate limits being non-overridable: some controls are boundaries, not knobs.)
Lifecycle: draft → running → paused → completed
An experiment has a state machine, because "is this test live" needs to be unambiguous:
- Draft — configured but not splitting traffic yet.
- Running — actively assigning variants and recording results.
- Paused — assignment frozen; existing users keep their variant, no new splits.
- Completed — the winner is chosen; traffic consolidates to it.
Crucially, moving to completed doesn't strand the cohort — everyone routes to the winning variant. And because assignment was deterministic, the results you're deciding on are the results you can reproduce.
Measuring the result honestly
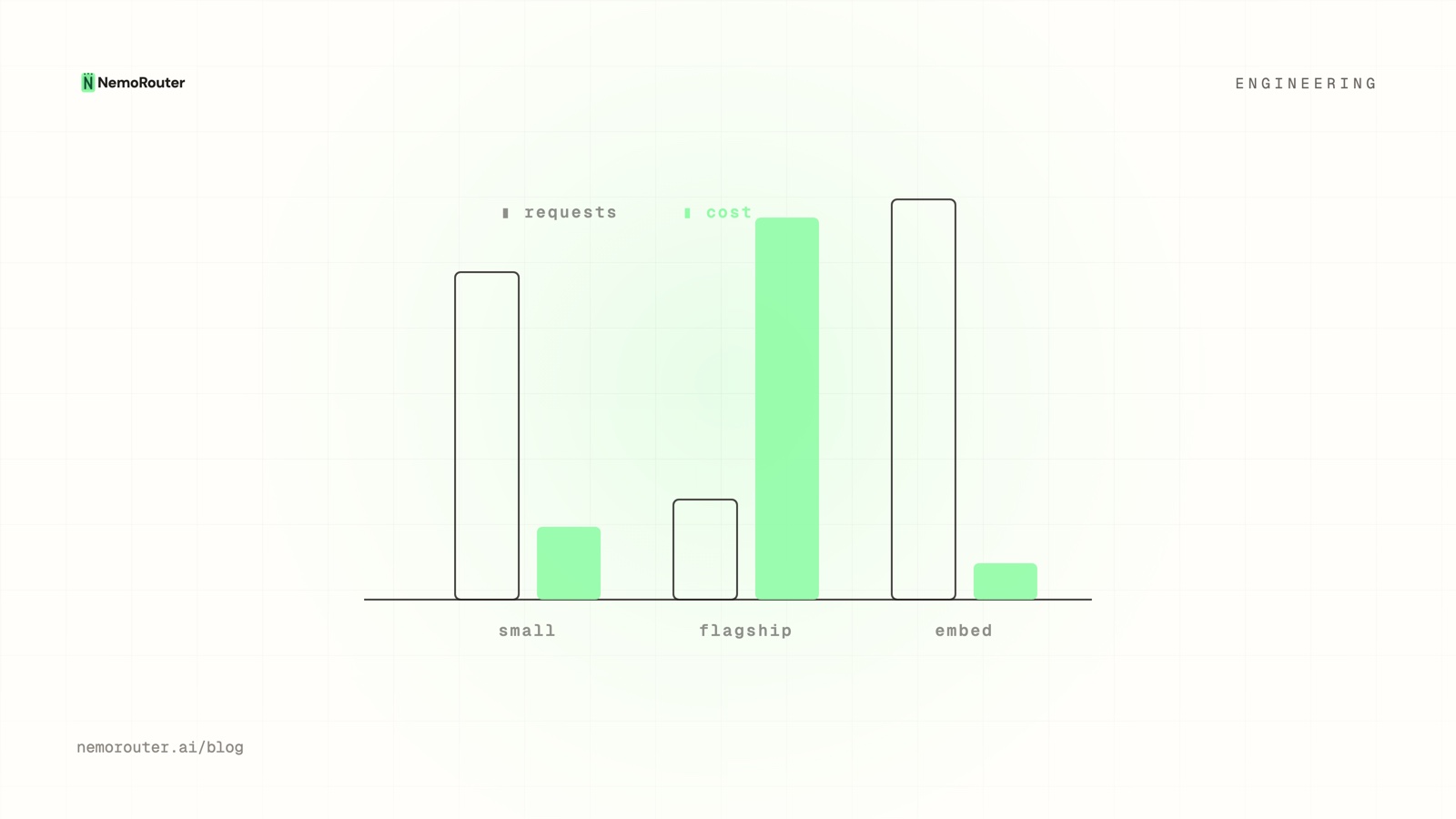
With stable assignment, your metrics finally mean something: compare cost-per-request, latency, and whatever quality signal you capture (thumbs, task success, downstream conversion) between cohorts that each saw exactly one variant. Pair this with cost-vs-usage analytics to confirm that "cheaper variant B" actually moved the bill, not just the request count.
The takeaway
A model comparison is only as trustworthy as its split. Random-per-request splitting manufactures noise; deterministic hash-based assignment gives each user a stable variant, keeps the split uniform and unbiased across users, and makes the experiment reproducible. Define the test, let the gateway assign, and read a result you can actually stand behind. Start in Router Settings → A/B Tests.