Engineering
Cost vs Usage: Finding the Quietly Expensive Model
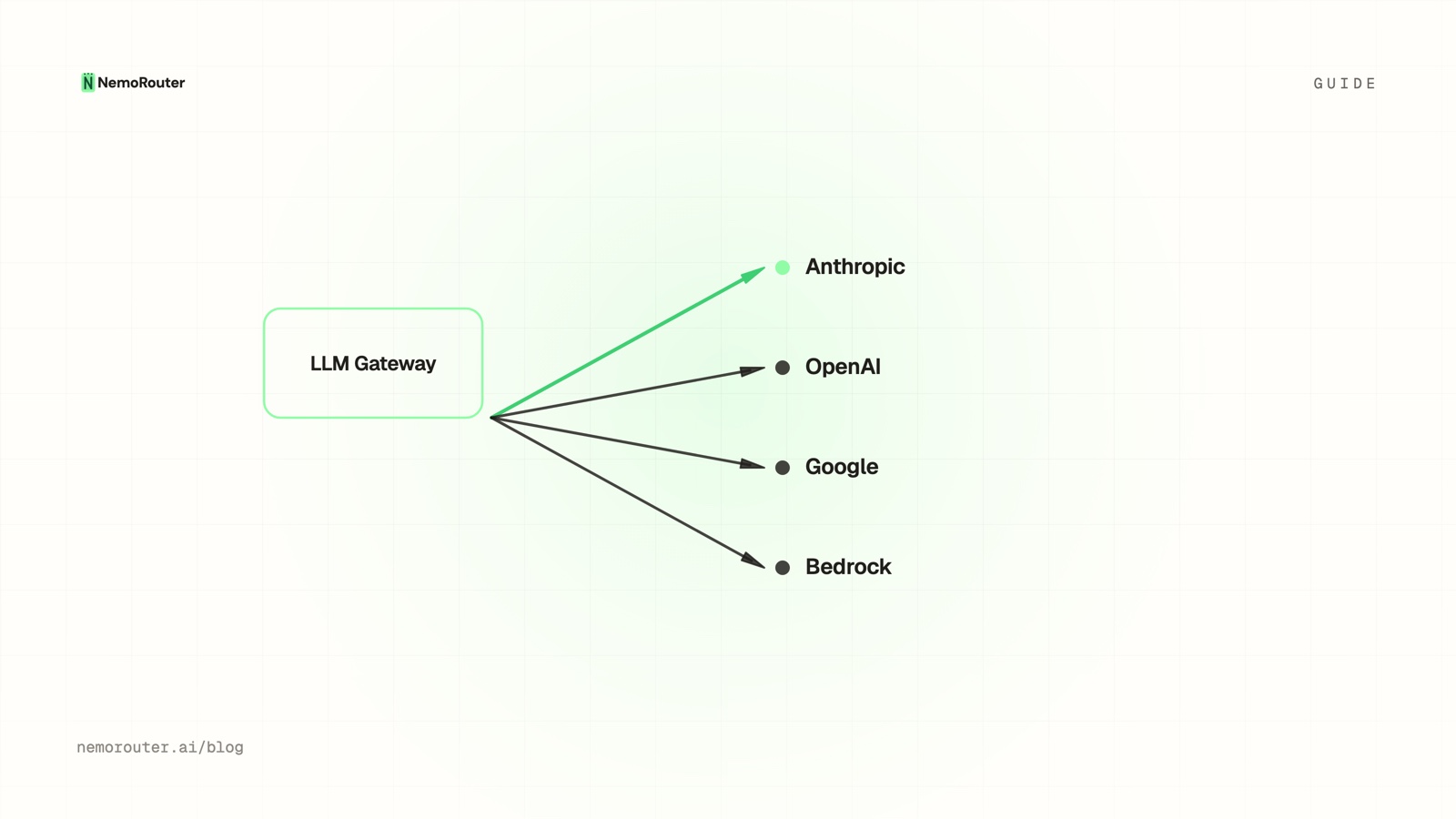
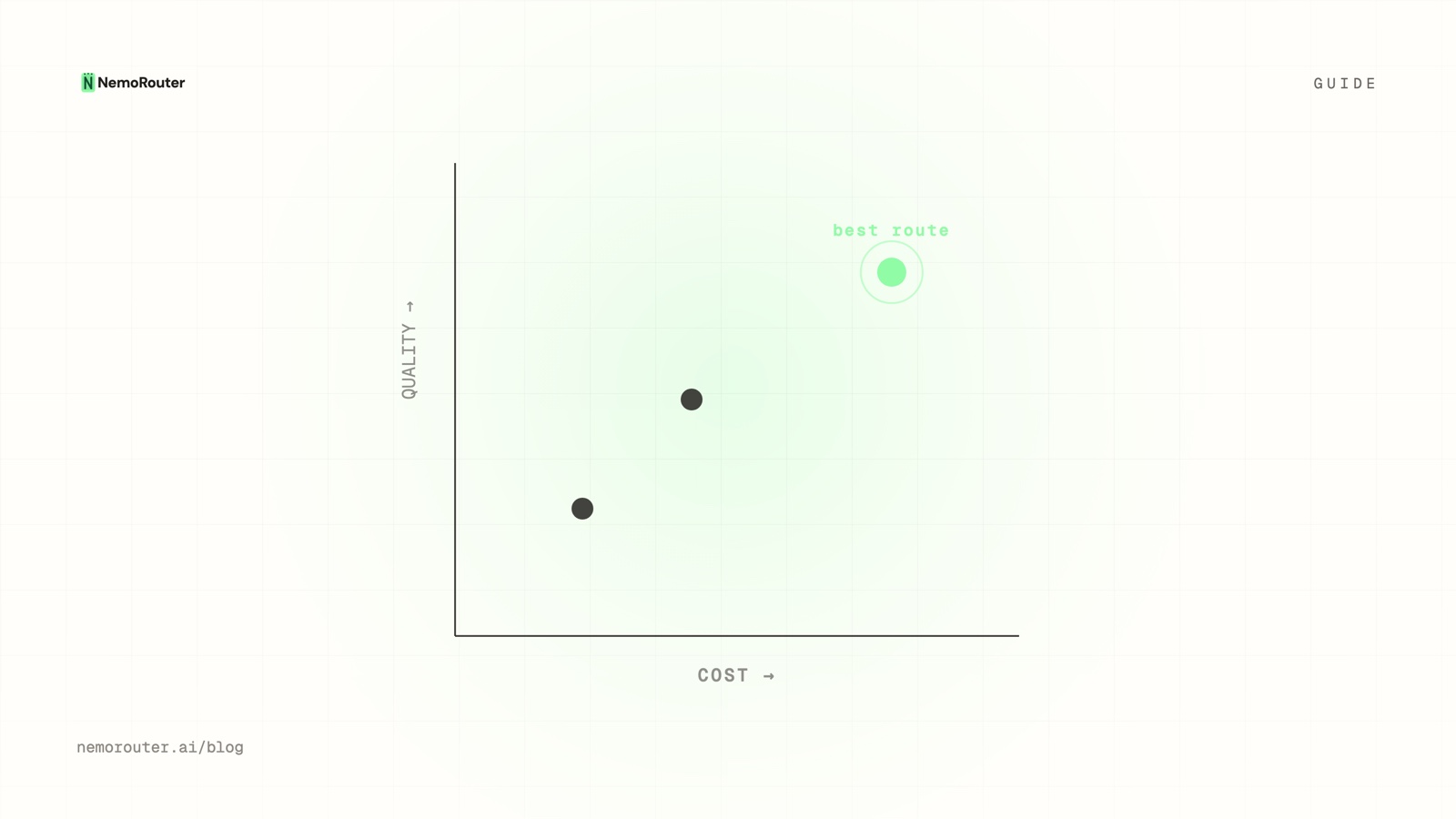
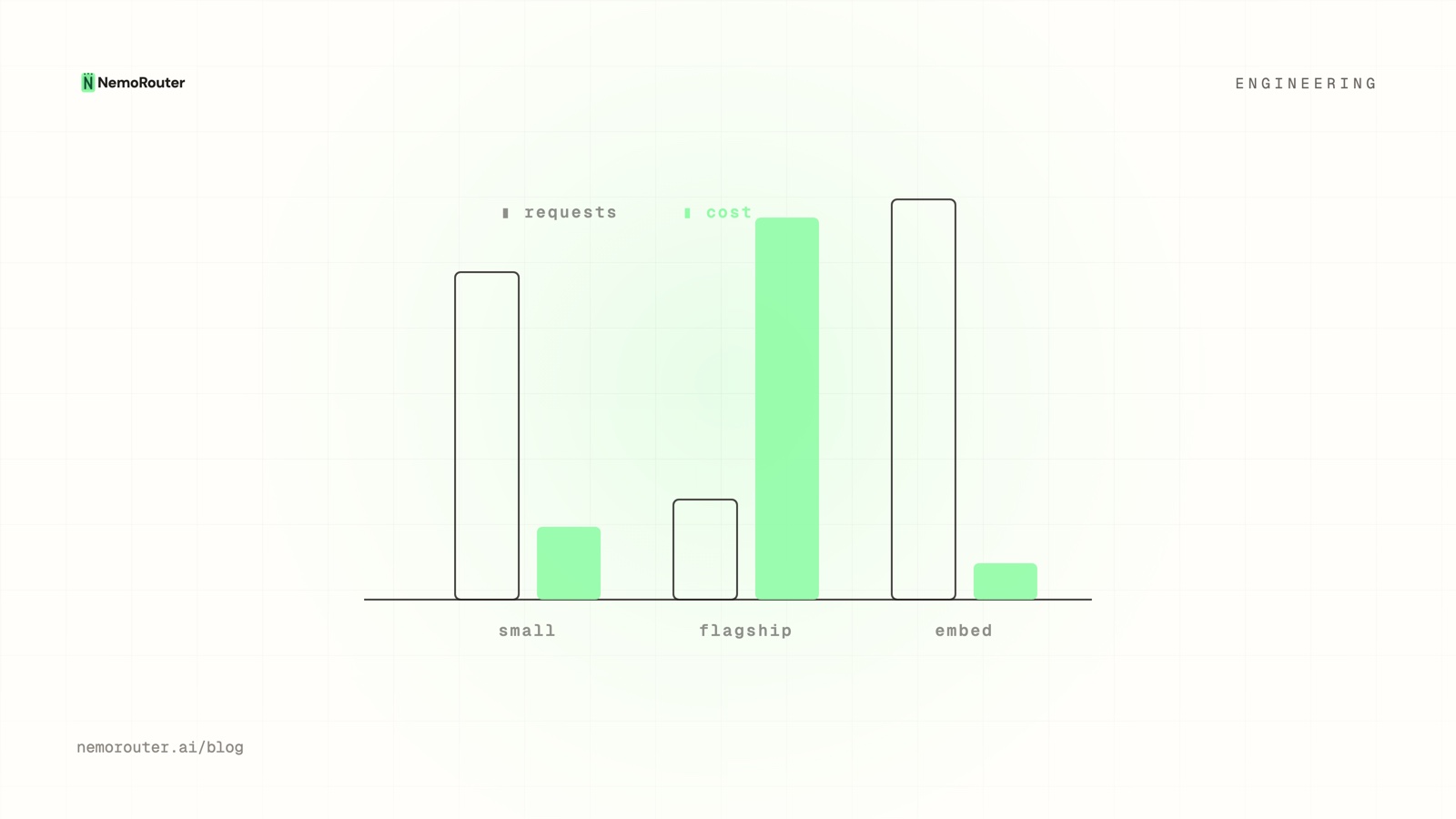
Request count and dollar cost tell different stories. Here is how cost-vs-usage analytics surface the low-volume model that dominates your bill — and the cheap one you can route more traffic to.
Nemo Team
8 min