If you call more than one model — or even one model from more than one place in your codebase — you eventually build a small layer in front of it: a place to keep the API key, count the cost, retry on failure, and swap providers without touching every call site. That layer is an LLM gateway. This primer explains what it is, what problems it solves, and how to tell a good one from a thin proxy.
What is an LLM gateway, exactly?
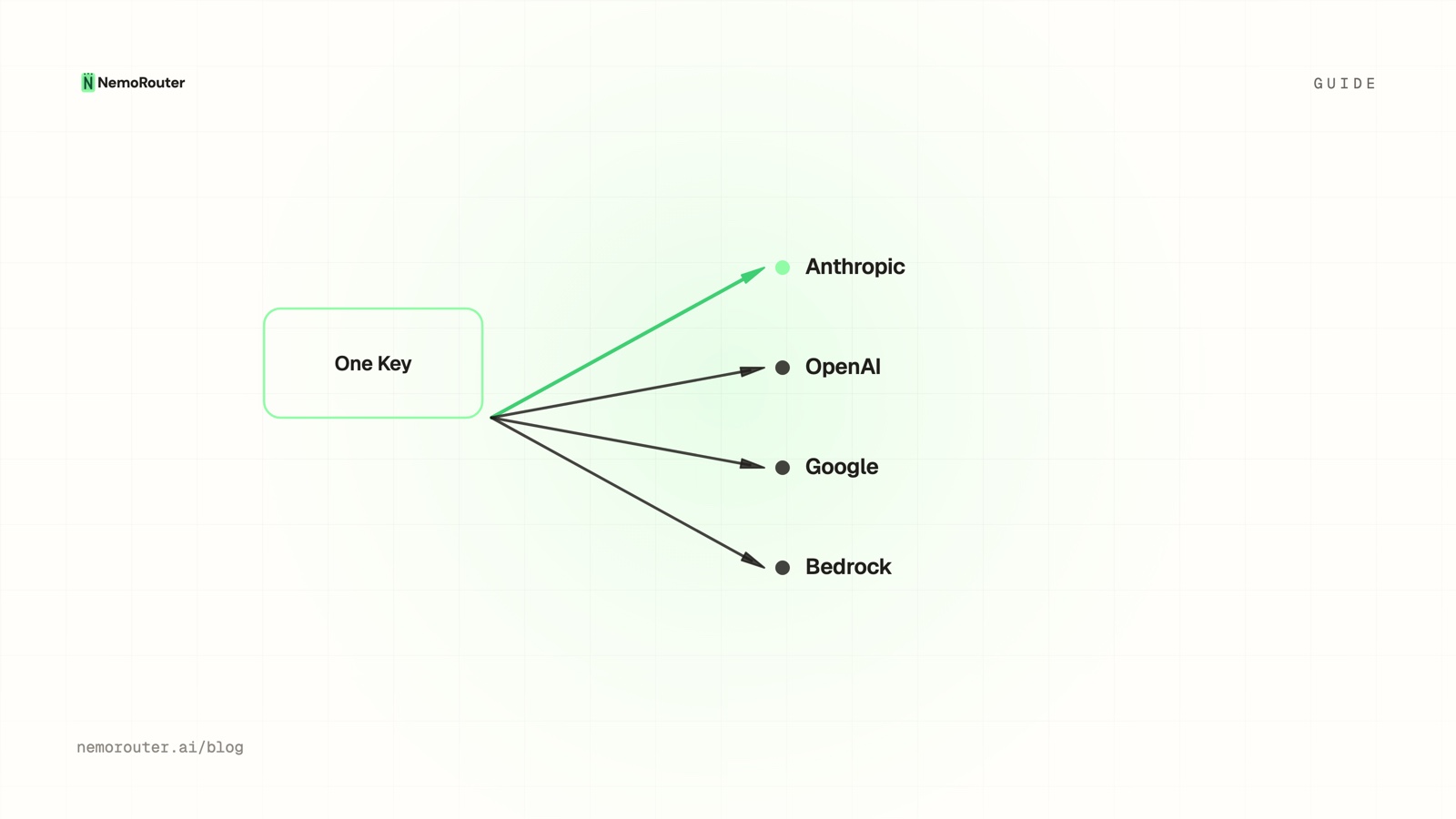
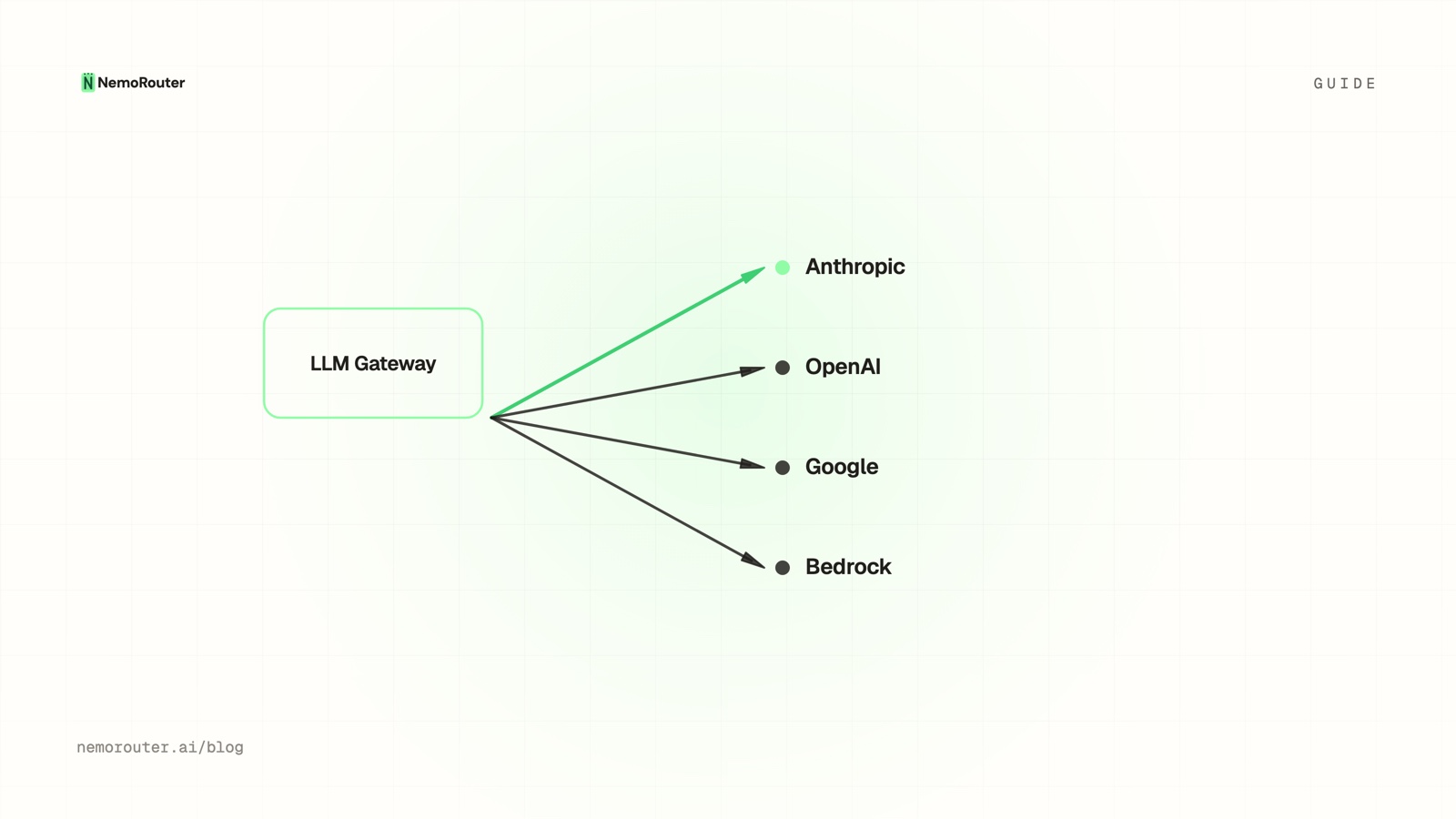
An LLM gateway is a single API endpoint that sits between your application and every model provider (OpenAI, Anthropic, Google, and others). Your code talks to one endpoint with one key; the gateway routes each request to the right provider and handles the cross-cutting concerns that every LLM call needs:
- One key, many models — your app authenticates once, not per provider.
- Cost tracking — every call's spend is measured and attributed.
- Rate limits and budgets — throughput and dollar ceilings you control.
- Guardrails — PII redaction, injection defense, content policy.
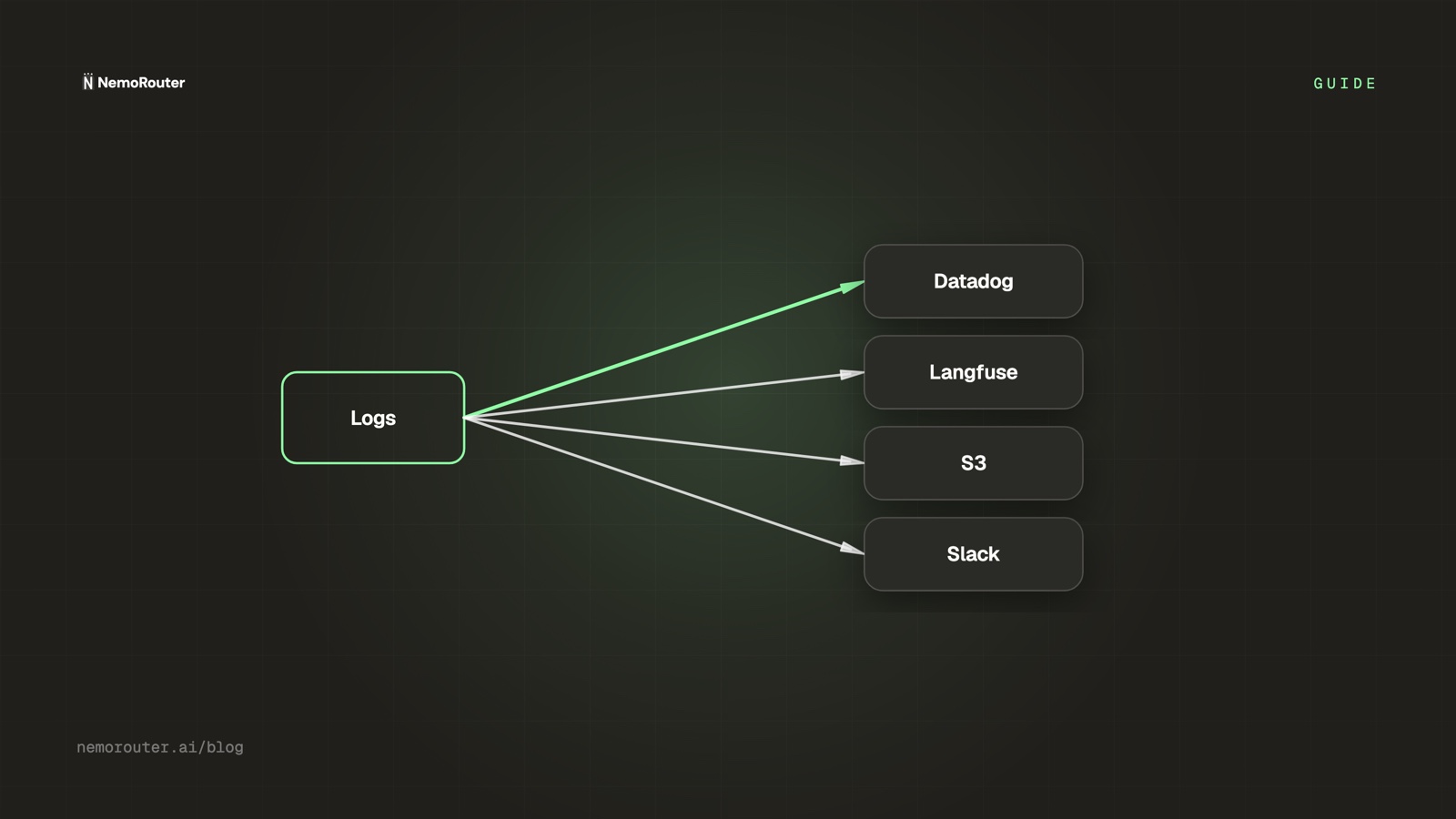
- Observability — logs, latency percentiles, and usage analytics.
- Reliability — fallback to another provider when one fails.
The defining property: your application code stops caring which provider serves a request. It asks for a model; the gateway does the rest.
Why not just call the provider SDK directly?
Calling openai.chat.completions.create() directly is fine for a prototype. It stops being fine the moment any of these is true:
| You have… | …and direct SDK calls cost you |
|---|---|
| More than one provider | N SDKs, N keys, N billing dashboards to reconcile |
| More than one team | No per-team cost attribution or budget |
| Production traffic | No fallback when a provider 5xxs or rate-limits you |
| Sensitive data | No inline PII redaction or injection defense |
| A finance team | Spend is a monthly surprise, not a real-time number |
A gateway turns all of those from "build it yourself, per provider" into "configuration." That's the trade: a few milliseconds of pass-through latency in exchange for not re-implementing cost, safety, and reliability at every call site.
Public gateway vs self-hosted vs managed
There are three shapes on the market, and they make different trade-offs:
- Public/aggregator gateways route to many models but often add a markup on top of provider pricing and give you limited governance.
- Self-hosted gives you full control but hands you the ops: scaling, upgrades, the database, on-call.
- Managed gateways run the infrastructure for you with the governance layer built in — keys, budgets, RBAC, observability — without the ops burden or the per-call markup.
NemoRouter is the third kind: a managed gateway where you get the enterprise governance features without self-hosting and without a per-token markup. You buy credits, you get 100% of them, and the platform fee is charged on top at purchase time — not skimmed from every call.
How do I evaluate one?
Cut through the marketing with these questions:
- Is cost tracking exact or estimated? A real gateway reads the provider's authoritative cost, it doesn't guess from token counts.
- Can I cap spend, and is the cap exact under concurrency? Ask specifically what happens when many requests race the last dollar. (Our answer: reserve-and-settle.)
- Are safety features gated behind a tier? PII redaction you have to upgrade to buy is a red flag.
- What happens when a provider goes down? Fallback should be a config line, not a redeploy.
- Is governance multi-tenant? Per-team budgets, per-key limits, and RBAC matter the moment more than one person uses it.
- What's the real price? Separate the provider cost from the gateway's cut. "Free" gateways often make it back on markup.
When do I actually need one?
You're ready for a gateway when you can answer "yes" to any of: I call more than one model; more than one team shares the spend; this is going to production; or I handle data I can't afford to leak. Below that bar, the provider SDK is fine. Above it, a gateway saves you from re-building cost, safety, and reliability by hand — badly, and once per provider.
The takeaway
An LLM gateway is the seam between your app and the model market: one endpoint, one key, one bill, with cost, safety, and reliability handled centrally instead of scattered across call sites. The good ones are exact about cost, honest about price, and don't put safety behind a paywall.
Want to see one in action? Try the playground, browse the models, or read the docs.