Credits are the product. If a balance can go negative, inference was given away for free; if a cap can be crossed, a customer's spend control is a lie. So the rule is absolute: a balance may never go negative, and every change is recorded in a ledger. This post is how NemoRouter keeps that rule under concurrency, where the naive approach quietly fails.
Why isn't "check the balance, then call" enough?
The obvious design is check-then-act:
if balance >= estimated_cost: # 1. check
response = await provider.call() # 2. act
balance -= actual_cost # 3. debitThis is a textbook race. Imagine a balance of $1.00 and ten concurrent requests, each costing ~$0.30. Every one of them reads balance >= cost at step 1 before any of them reaches step 3. All ten proceed. The balance ends at -$2.00. The check passed for everyone because nobody had committed a debit yet.
Concurrency is the default, not the exception
An LLM gateway's whole job is fan-out: agent swarms, batch jobs, and parallel tool calls all issue many requests at once on the same key. "It works when I test it by hand" means nothing — the failure only shows up under the load the product is designed to handle.
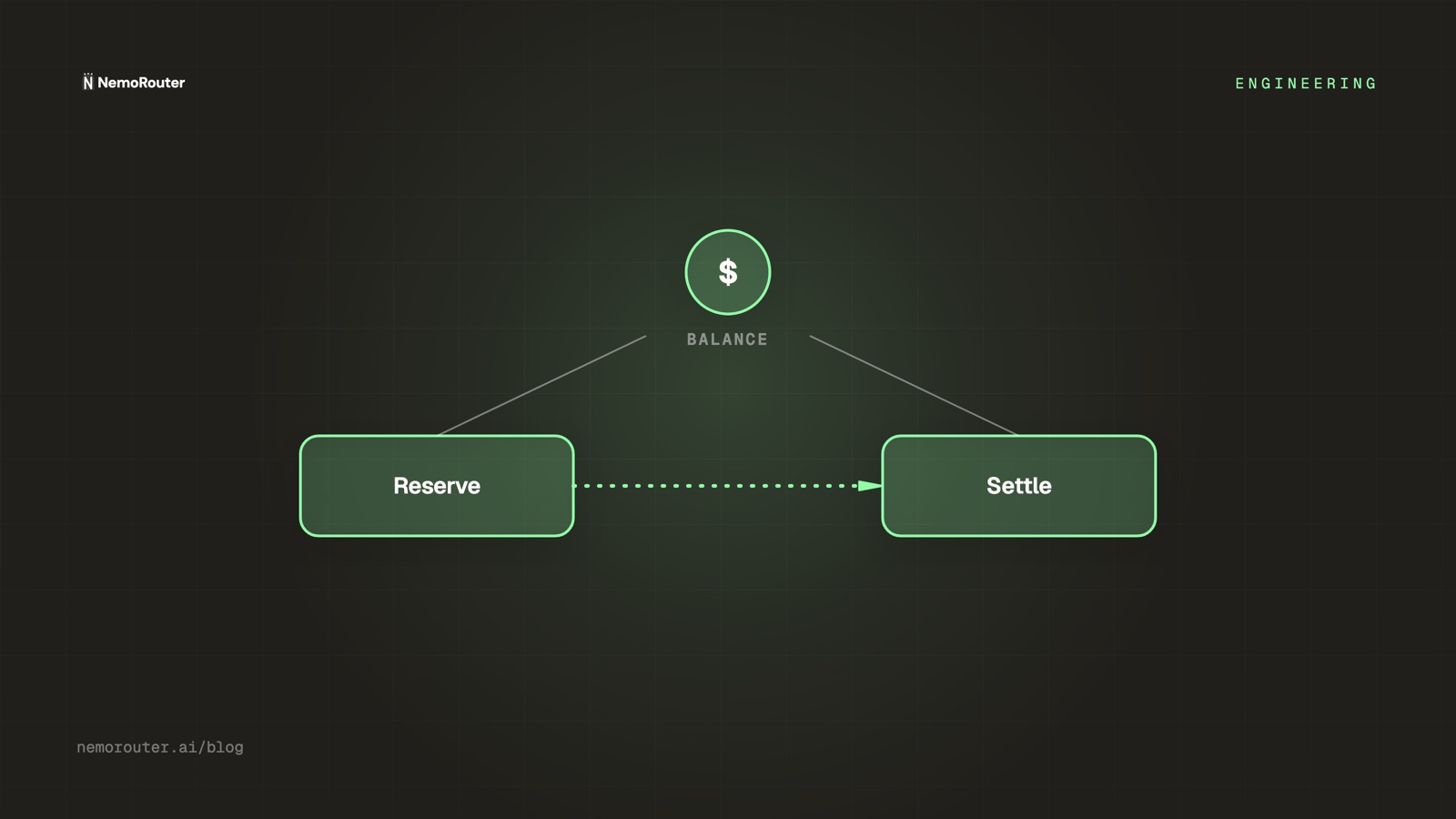
The fix: reserve before you call
Reserve-and-settle splits the single debit into three steps, and crucially moves the money-holding step to before the upstream call:
reserve → atomically hold an ESTIMATE against the balance.
If the hold can't fit, return 402 now — no call is made.
forward → send the request to the provider.
settle → replace the estimate with the REAL cost of the call;
release the difference.
release → on ANY failure path, hand the full reservation back.The reservation is an atomic operation: it both checks headroom and commits the hold in one indivisible step. Two requests can no longer both "see" the last dollar — the first reserves it, the second finds nothing left and gets a clean 402.
Every failure path — a provider timeout, a guardrail block, a client disconnect — must release the reservation. A reservation that is never settled or released is a leaked hold: the customer's headroom shrinks for a call that never cost anything. A leaked reservation is treated as a bug of the same severity as a negative balance.
How do we estimate before we know the cost?
The gateway reserves the maximum plausible cost of the call, not the expected cost. For a chat completion that means pricing the requested output ceiling at the model's output rate, plus the measured input tokens. The estimate is deliberately high — over-reserving briefly is safe (it can only reject a call that was near the edge), while under-reserving re-introduces the overspend race.
At settle time the gateway uses the authoritative cost of the completed call and releases the gap between estimate and actual back to the balance. The customer only ever pays the real number; the over-reservation exists for milliseconds.
| Phase | Balance effect | Source of the number |
|---|---|---|
| Reserve | − estimate (held) | output ceiling × output price + input tokens × input price |
| Settle | + (estimate − actual) | the call's authoritative final cost |
| Release (on failure) | + estimate | the original reservation |
What makes the hold atomic?
Two properties:
- The reserve is a single conditional update. The check ("does the available balance cover this estimate?") and the hold commit in one indivisible step that either takes the hold or does nothing (→
402). There is no window between the check and the hold for another request to slip through. - Balance and ledger move together. Every change to a balance writes a matching row to the credit ledger in the same operation. If the ledger write fails, the balance change rolls back. This is what makes the ledger a source of truth rather than a log that hopefully agrees — balance is always reconstructable by summing ledger entries.
Why a ledger, not just a number
A bare balance column tells you the "what" but never the "why." The ledger makes every cent auditable: each reservation, settlement, release, top-up, and platform fee is a row. When finance asks "where did $4.12 go," the answer is a query, not an investigation.
Testing the invariant, not the happy path
A single-threaded test can't prove a concurrency property. The way to validate spend safety is to fire many simultaneous requests at a tiny balance and assert two things afterward:
- the balance is never negative at any observed point, and
- the sum of all ledger entries equals the final balance, exactly.
Some calls succeed and the rest get a clean 402 — none overspend. Running this on every build means a regression that re-introduces the check-then-act race is caught loudly, before it can ship.
The takeaway
Spend safety is a concurrency problem wearing a billing costume. The moment you treat "check the balance" and "spend the money" as two steps, a race exists. Reserve-and-settle collapses the check and the hold into one atomic act, settles to the real cost of the completed call, and backs every move with a ledger row.
The customer-facing result is the spend limits and budgets that actually hold — because underneath them, the accounting can't be raced.