Every model provider has bad days: a regional outage, a capacity crunch that turns into 429s, a slow degradation that times out your requests. If your app calls one provider directly, its bad day is your bad day. A fallback chain turns a provider outage from an incident into a non-event — the gateway reroutes to a healthy provider mid-request, and your users never notice.
What is a fallback chain?
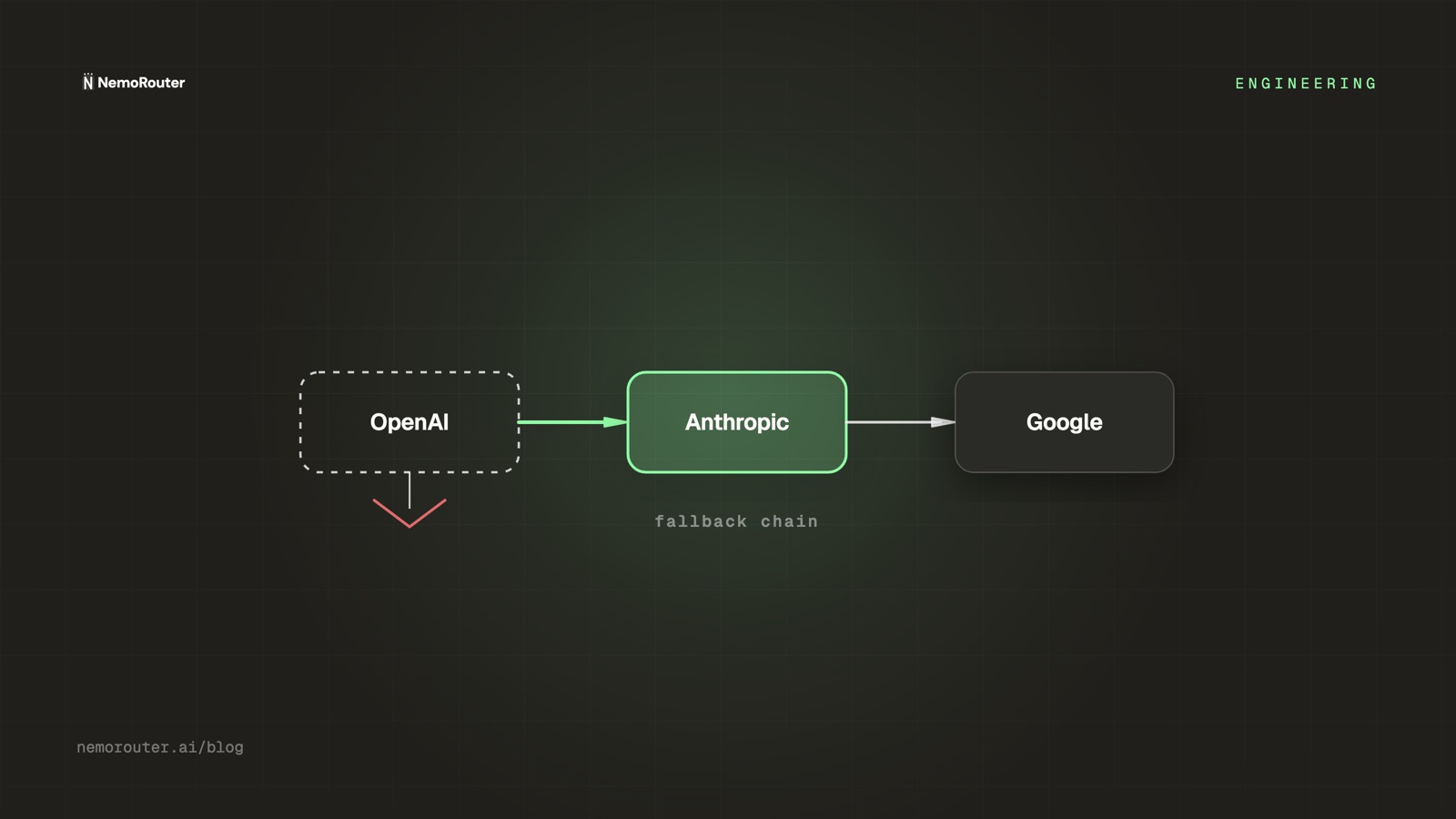
A fallback chain is an ordered list of routes the gateway tries for a given request. If the first fails in a retryable way, it tries the second, and so on, until one succeeds or the chain is exhausted:
request for "best-chat"
├─ try Anthropic claude-sonnet-4-6 → 529 overloaded
├─ try OpenAI gpt-class equivalent → 200 OK ✅ returned to caller
└─ (would try a third if needed)The caller asked for a capability ("best-chat"), not a specific provider endpoint. That indirection is what makes fallback possible: the gateway is free to satisfy the request from whichever route is healthy, because the client never hardcoded one.
What counts as a retryable failure?
Not every error should trigger a fallback. Falling back on the wrong errors is worse than not falling back at all — you'd retry a bad request several times and multiply the cost. The line:
| Failure | Fall back? | Why |
|---|---|---|
429 / 529 (rate-limit, overloaded) | Yes | Transient; another provider has capacity |
500 / 503 / timeout | Yes | Provider-side, likely transient |
400 (malformed request) | No | The request is bad everywhere; retrying wastes money |
401 (auth) | No | A key problem won't fix itself on provider #2 |
| Guardrail block | No | A policy decision, not a failure |
The chain only advances on errors that a different healthy provider could plausibly succeed at. Client errors fail fast.
Fallback is not free latency
Each hop in the chain adds a round trip. A request that falls back twice took roughly three providers' worth of wall-clock — which is exactly the kind of thing that widens your p99 tail. Order the chain so the fastest, most-reliable route is first, and keep chains short. Fallback buys availability; pay for it deliberately.
Cost and credits across a fallback
A subtle point most "retry" implementations get wrong: only the successful call should be billed. When the gateway reserves credits for a request (see reserve-and-settle), a failed first hop must not settle a charge — the reservation carries through to the route that actually serves the request, and only that route's authoritative cost is settled. A fallback that left a phantom charge for the failed attempt would make outages cost customers money, which is exactly backwards.
So the accounting is: reserve once, try the chain, settle the winner's real cost, release the rest. The customer pays for one successful call regardless of how many routes were attempted.
Ordering the chain
A good chain is ordered by a blend of three factors:
- Reliability first — your most consistently-available route leads, so the common case is one hop.
- Latency second — among reliable routes, the faster one goes earlier to protect your tail.
- Cost as a tiebreaker — when two routes are equally good, the cheaper one leads.
Resist making the cheapest route first if it's also the flakiest — you'll fall back constantly, and the latency and complexity cost outweighs the per-call savings. The point of the chain is availability; optimize it for that, and let dedicated cost-vs-quality routing handle the spend trade-off separately.
Testing the unhappy path
You can't trust a fallback you've never seen fire. The way to test it is to force the first route to fail — point it at a deliberately-broken target or simulate a 529 — and assert that (a) the request still returns 200 from the next route, and (b) exactly one successful call was billed. An untested fallback chain is a comforting config line that may or may not work when the outage you bought it for actually arrives.
The takeaway
A fallback chain is the difference between "OpenAI is down" being an incident and being a log line. Define the chain by capability not provider, advance only on retryable failures, bill only the successful hop, and order by reliability-then-latency-then-cost. Then the next provider outage is something your gateway handles while you sleep. Configure chains in Router Settings.