You can put a hard dollar ceiling on every API key, team, and org — and once that ceiling is hit, the next request is rejected instead of billed. That single guarantee is what turns AI from an open-ended line item into a number you can actually plan around.
If you run LLM features in production, the scary cost isn't the steady-state spend you forecasted. It's the 3 a.m. retry loop, the agent that fans out a thousand calls, or the launch that goes 10× overnight. NemoRouter gives finance-aware engineering leaders a way to cap all of that before it happens — not reconcile it after.
The problem this solves
Most teams discover their AI bill is wrong at the end of the month, when it's already spent. The usual tools are alerts and dashboards, but an alert is a notification, not a brake — by the time it fires, the money is gone.
The failure modes are predictable:
- A runaway agent. One buggy loop or an unbounded tool call can burn a month's budget in an afternoon.
- A traffic spike. A successful launch or a scraper hits your endpoint and spend tracks demand with no upper bound.
- No attribution. When the bill arrives, you can't tell which customer, team, or feature drove it, so you can't fix the right thing.
Predictability requires a hard stop, not a warning. The ceiling has to live in the request path so it can refuse work the moment a limit is reached.
How it works
NemoRouter sits in front of every model behind one OpenAI-compatible API key. Because every call passes through the gateway, every call can be checked against the budgets and rate limits you've set — at the key, team, and org level — before it's allowed to run.
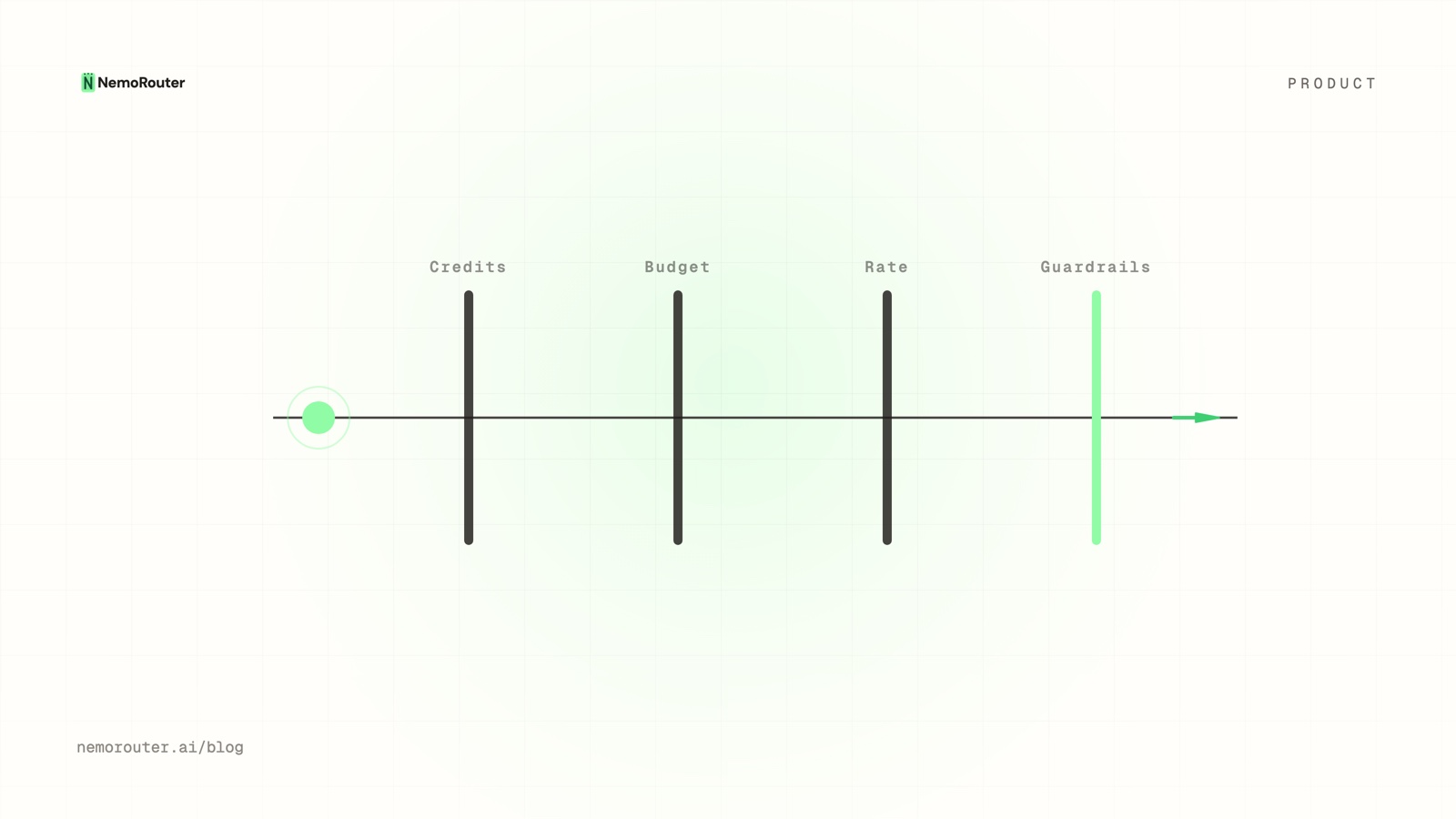
The ceilings are independent and stack. A key can have its own monthly cap; the team that owns it has a cap; the org above that has a cap. A request has to clear all of them. When any ceiling is reached:
- A spend ceiling returns a
402(payment/budget exhausted). - A rate ceiling returns a
429(too many requests / tokens per minute).
Both are standard HTTP responses your client already knows how to handle, so a hit limit degrades gracefully — you queue, back off, or surface a clean message — instead of producing an invoice.
Every response also carries its own cost on the x-nemo-request-cost header, so you can attribute spend per request, per customer, or per feature in real time rather than waiting for a monthly statement.
A working example
Point the standard OpenAI SDK at NemoRouter and handle the budget response like any other status code:
from openai import OpenAI, APIStatusError
client = OpenAI(base_url="https://api.nemorouter.com/v1", api_key=key)
try:
resp = client.chat.completions.create(
model="nemo/cost-optimized",
messages=[{"role": "user", "content": prompt}],
)
cost = resp.headers.get("x-nemo-request-cost") # attribute this call now
print(f"served — this request cost {cost}")
except APIStatusError as e:
if e.status_code == 402:
print("budget ceiling reached — request refused, no charge")
elif e.status_code == 429:
print("rate ceiling reached — back off and retry")
else:
raiseThe key is paired with a budget you set once; the gateway enforces it on every call without any change to your code.
Set the ceiling per customer, not just per app
If you resell AI to your own customers, give each one their own key with its own
budget. A single customer can never spend past their cap, and the
x-nemo-request-cost header lets you bill them for exactly what they used.
The results
What changes when the ceiling lives in the request path instead of in a dashboard:
| Capability | Alerts-only setup | NemoRouter budgets |
|---|---|---|
| Surprise bill from a runaway agent | Possible — alert fires after spend | Impossible — request rejected at the cap |
| Per-key / team / org limits | Manual, after the fact | Enforced before each call |
| Cost visibility | End of month | Real time, per request |
| Per-customer attribution | Spreadsheet reconciliation | x-nemo-request-cost per call |
| Cost of the feature | Often a paid tier | Free on every tier |
Verified June 2026.
Budgets, rate limits, and guardrails are not an enterprise upsell — they're included on every tier. NemoRouter's only pricing variable is the platform fee on top of provider cost: 0% on annual prepay, 2% monthly, 4% pay-as-you-go. The controls that make spend predictable stay free regardless of which you choose.
Summary
Predictable AI spend isn't about forecasting better — it's about making the worst case impossible. With hard budgets at the key, team, and org level, a runaway agent or a traffic spike hits a ceiling and stops, so the only way to spend more is to deliberately raise the limit. Pair that with real-time, per-request cost attribution and you can plan, price, and resell AI with confidence. See how the limits compose in the four budget ceilings guide.