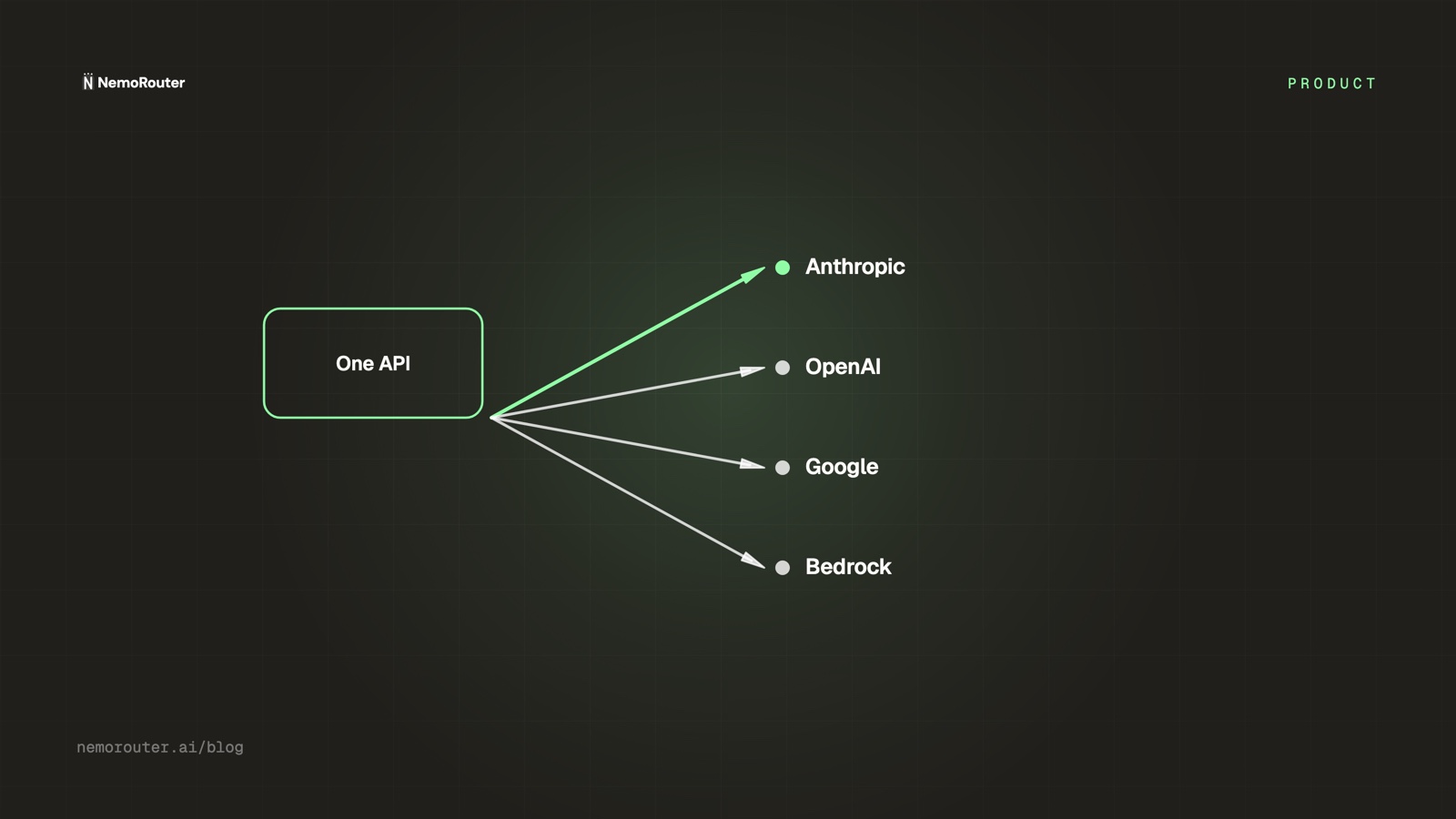
One OpenAI-compatible API key gives you 78+ models from Anthropic, Google, and OpenAI today — with AWS Bedrock shipping next. You pick the model per request by changing a single string; everything else in your code stays exactly the same.
That's the whole promise: stop maintaining a different SDK, a different key, and a different billing relationship for every provider. Point your existing code at one endpoint and reach the entire model landscape behind it. This post shows what that buys an engineering team and how little has to change to get it.
The problem this solves
Multi-model is now the default, not the exception. You want Claude for reasoning-heavy tasks, Gemini for long context, a smaller OpenAI model for cheap classification — and the model you'll want next quarter doesn't exist yet. The cost of that ambition is usually plumbing.
Each provider ships its own SDK, its own authentication, its own request and response shape, and its own dashboard. Adding a provider means a new key to rotate, a new client to wrap, a new billing portal to reconcile, and a new set of edge cases to handle. Teams end up writing an in-house abstraction layer just to keep the rest of the codebase sane — and then they own that layer forever. Worse, every line of provider-specific code is a small vote for vendor lock-in: the more you wire into one SDK, the harder it is to move.
The result is that "let's try a different model" becomes a sprint instead of a one-line change.
How it works
NemoRouter sits in front of every provider as a single OpenAI-compatible endpoint. You keep using the OpenAI SDK you already know — you just change the base_url and use a NemoRouter key. The model you want lives in the model field, and switching providers is switching that string.
Because the contract is OpenAI-compatible, the libraries, frameworks, and agent tooling you already use keep working. Responses come back in the shape your code expects, and useful metadata rides along on documented headers — x-nemo-routed-model tells you which model actually served the request, and x-nemo-request-cost gives you the exact cost. Adopting a model that launched this morning is a config change, not a migration.
A working example
The only thing that changes from a standard OpenAI integration is the base URL and the key. Here's the same client calling three different providers:
from openai import OpenAI
client = OpenAI(
base_url="https://api.nemorouter.com/v1",
api_key=NEMO_API_KEY,
)
for model in ["anthropic/claude-opus-4-8", "google/gemini-2.5-pro", "openai/gpt-5"]:
resp = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Summarize this contract in 3 bullets."}],
)
print(model, "→", resp.headers["x-nemo-routed-model"])No new SDK, no extra keys, no per-provider client. Changing model is the entire diff between using Claude and using Gemini.
One key, every team
A single NemoRouter key can reach every model, but you don't have to hand the whole catalog to everyone. Scope keys per team or project and apply budgets and guardrails on top — the access surface is one API, the controls are yours.
The results
The payoff shows up as plumbing you no longer write and decisions you no longer have to defer:
| Without one API | With NemoRouter |
|---|---|
| One SDK + key + dashboard per provider | One OpenAI-compatible key for all |
| New provider = new integration sprint | New model = change one string |
| Custom in-house abstraction to maintain | Standard contract, nothing to own |
| Billing reconciled across N portals | One bill, per-request cost on a header |
| Switching models is a migration | Switching models is a config change |
The strategic benefit is optionality. When pricing shifts, when a new model leads a benchmark, or when a provider has a bad week, you can move traffic without touching application code — because nothing in your codebase is married to a single vendor's SDK.
Model count and providers verified June 2026; AWS Bedrock is shipping next.
Summary
Accessing every AI model through one API turns "which provider?" from an architecture decision into a per-request choice. You write to one OpenAI-compatible endpoint, you reach 78+ models across Anthropic, Google, and OpenAI today, and you adopt whatever comes next by editing a string instead of onboarding a vendor. To see the exact request and response contract, read the docs.