If you're building an AI product, "the model bill" is the wrong unit. The question that decides whether your business works is per customer: what does it cost to serve this account, is that customer profitable, and can I bill them for what they actually used? A gateway that only gives you one monthly total can't answer any of those. Here's how to get per-customer economics out of your LLM spend without building a metering system yourself.
The unit-economics problem
Your AI feature calls models on behalf of many customers. At month end you have one provider bill and no idea how it splits. That's fine until someone asks:
- Which customers are unprofitable? (heavy users on a flat plan)
- Can we offer usage-based pricing? (you'd need per-customer usage)
- What's our gross margin per account? (cost to serve vs revenue)
Without attribution, you guess. With it, you query. The gateway already sees every call and its exact cost — the trick is tagging each call with who it was for.
Attribute every call to a customer
Tag each request with the customer it serves (and the feature, while you're at it):
client.chat.completions.create(
model="claude-sonnet-4-6",
messages=[...],
extra_body={"metadata": {"tags": ["customer:acme", "feature:assistant"]}},
)Now every call's exact cost is indexed by customer. "What did Acme cost us this month" is a filter on the Cost report, summing to the real provider number — not an estimate, not a guess. (Full mechanics in cost attribution by tag.)
Attribution is metadata, authorization is not
Tag-based attribution tells you what a customer cost. It does not decide whose budget gets charged — that's tied to the authenticated key. Keep "measuring spend" and "authorizing spend" separate: a tag is for your books, not for access control.
Two models: shared key vs key-per-customer
There are two ways to structure this, and the right one depends on isolation needs:
| Model | How | Best when |
|---|---|---|
| Shared key + customer tag | One key, customer: tag per call | Many small customers; you just need attribution |
| Key (or team) per customer | A virtual key / team per customer | You need hard per-customer caps + isolation |
Tagging is the lightest path and gives you the breakdown. Promoting big or sensitive customers to their own key/team adds hard budget caps and rate limits per customer — so one customer's runaway can't eat another's headroom, and a leaked key is scoped to one account.
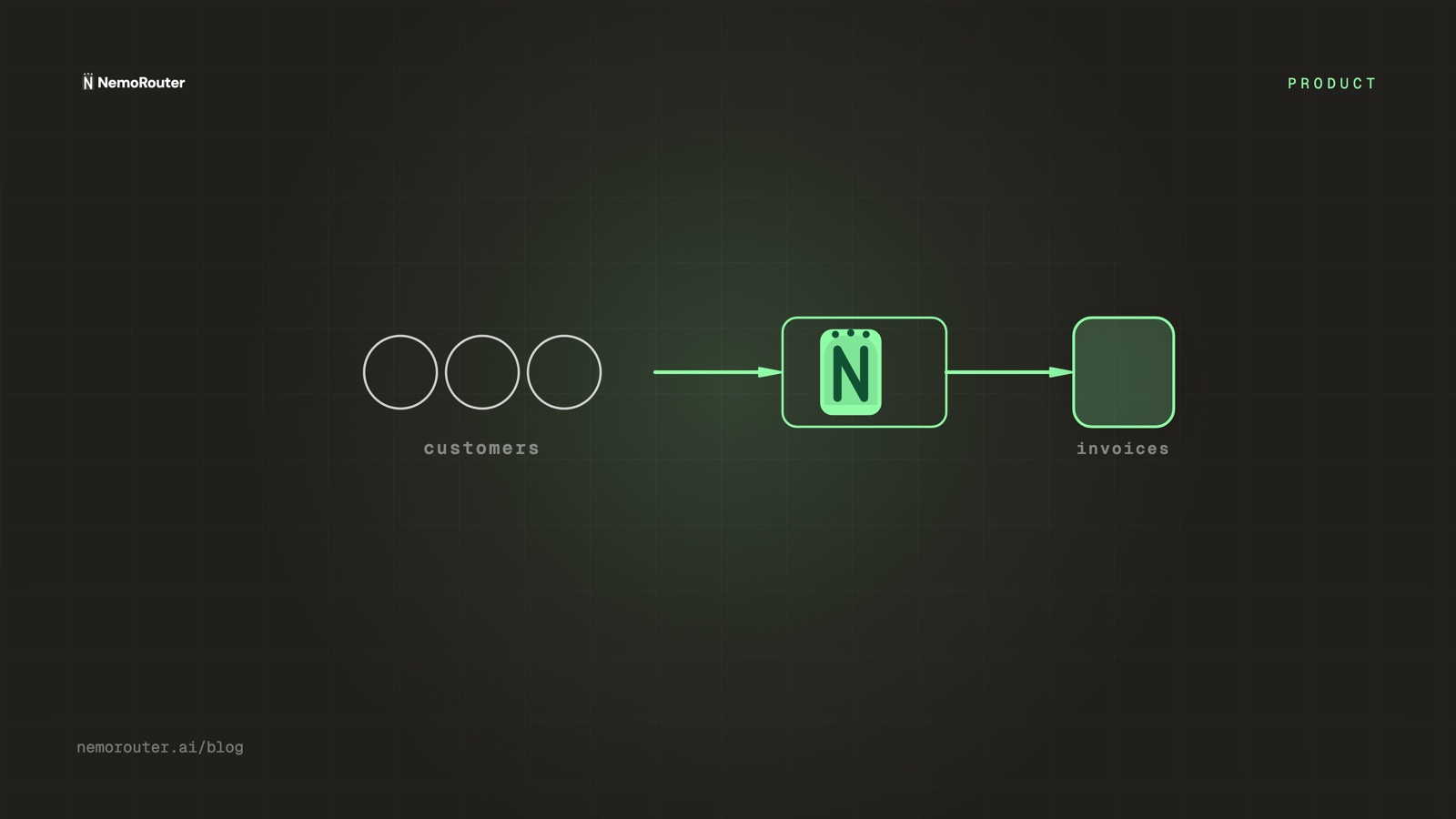
From attribution to invoices
Once spend is attributed, usage-based billing is a reporting step, not an engineering project:
1. tag every call with customer:<id>
2. at period end, sum cost per customer (Cost report / export)
3. apply your markup / plan → invoice line per customer
4. reconcile: sum of customer costs == your gateway billBecause the costs are the provider's settled numbers, step 4 reconciles exactly — there's no drift between "what we billed customers for" and "what we actually paid." That reconciliation is what makes usage-based pricing safe to offer: you're never billing on an estimate that could be wrong in either direction.
Margin, not just cost
The real payoff is margin visibility. With cost-per-customer in hand and revenue-per-customer in your billing system, gross margin per account becomes a join. You find the flat-plan customer whose usage makes them unprofitable, the enterprise account with huge headroom, and the feature that's quietly expensive across everyone (overlay cost-vs-usage analytics to spot it). Those are the inputs to pricing decisions you currently make blind.
The takeaway
Selling AI means caring about per-customer economics, and that starts with attribution. Tag every call with the customer, let the gateway sum exact costs per account, promote your heavy/sensitive customers to their own capped key, and reconcile to the bill. You go from "the model costs went up" to "Acme's margin is 60%, and here's the customer dragging it down" — the difference between running an AI business and hoping one works. Start in the Cost reports.