Most AI-gateway pages sell features; the people who approve the budget are buying four outcomes — lower spend, lower unit cost, better performance, and faster deployment. If your internal case lists capabilities instead of business results, it stalls at the first finance review.
This post reframes an LLM gateway the way a VP of Engineering, CTO, or Head of Platform actually has to pitch it: as four measurable outcomes, each mapped to a concrete NemoRouter capability — and why that framing wins approval that a feature list never will.
The problem this solves
A feature list answers "what does it do?" A budget owner is asking "what changes for the business?" Those are different questions. "We get guardrails, A/B testing, and prompt management" describes a tool. "We cut our model bill, ship the next AI feature in days instead of weeks, and stop one-off outages from paging the on-call" describes a result.
Buyers buy outcomes, not mechanisms. The mechanism is how you deliver — but it's the outcome that gets funded. So the case for a gateway should lead with the four things leadership already cares about, and treat the features as the proof, not the pitch.
How it works
A gateway sits as one OpenAI-compatible endpoint in front of every model provider. Your application keeps talking to one API; behind it, the gateway handles routing, budgets, guardrails, and cost tracking across 78+ models (Anthropic, Google, and OpenAI live today; AWS Bedrock shipping next).
That single seam is what makes the four outcomes possible. Because every request flows through one place, you can attribute cost, enforce a budget, switch a model, or apply a guardrail without touching application code.
A working example
Switching is a base-URL change — no rewrite, which is the whole "faster deployment" story in two lines:
from openai import OpenAI
client = OpenAI(base_url="https://api.nemorouter.com/v1", api_key=key)
resp = client.chat.completions.create(
model="nemo/cost-optimized",
messages=[{"role": "user", "content": prompt}],
)
print(resp.headers["x-nemo-request-cost"]) # exact cost of this callIllustratively: a team spending $20,000/month that routes routine traffic to a cheaper qualifying model and moves from pay-as-you-go to annual prepay changes both the unit cost and the platform fee it pays. The numbers depend on your traffic mix — the point is that all four levers live behind the same endpoint.
Lead with the outcome, prove with the feature
In your internal deck, put the business result on the slide title and the capability in the body. "Reduce AI costs" is the headline; "smart routing + per-team budgets" is the evidence.
The four outcomes, mapped
| Benefit | What it means for the business | How NemoRouter delivers it |
|---|---|---|
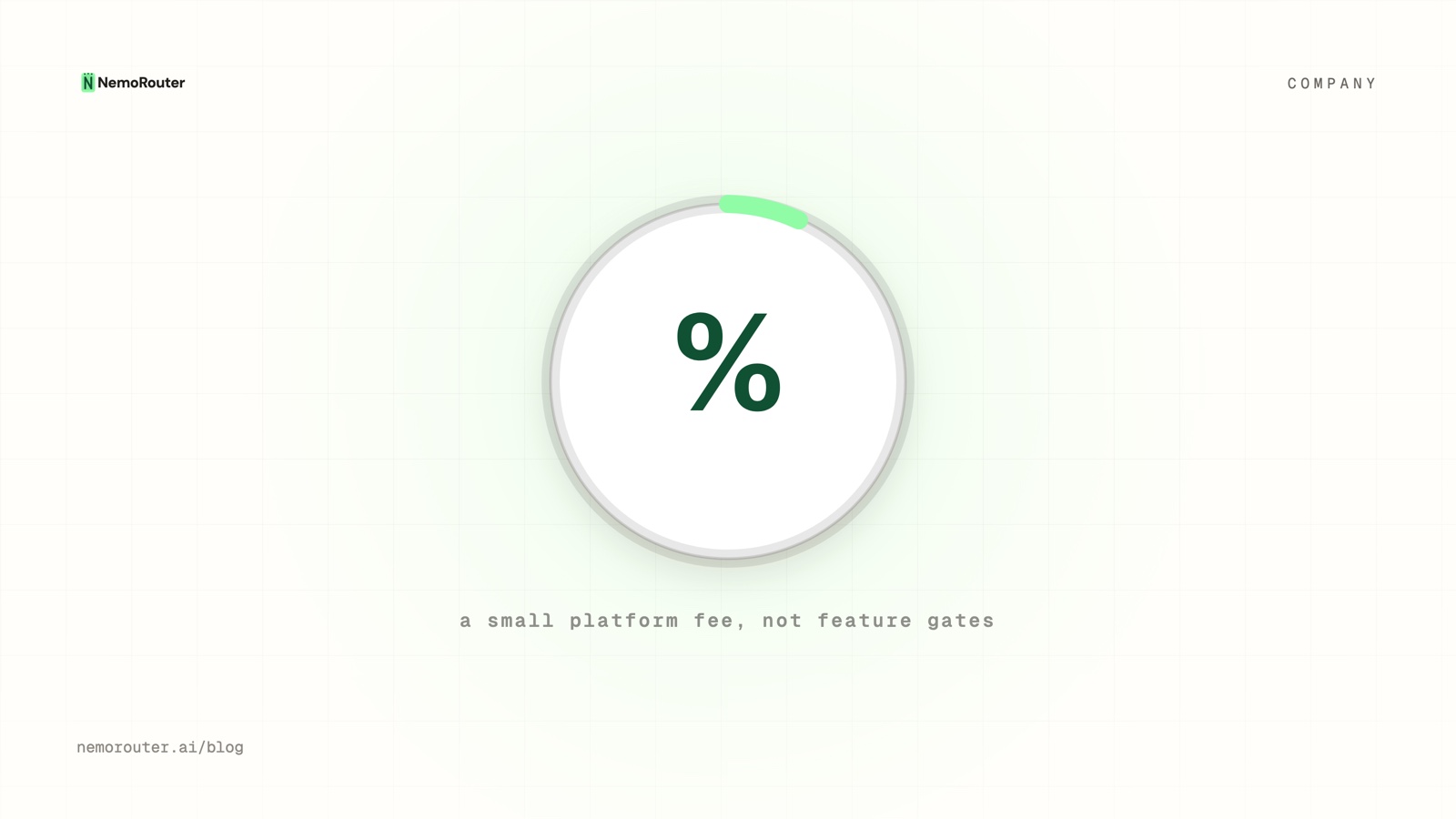
| Save money | Lower total spend on AI, including platform overhead, not just token price | Platform fee of 0–4% (0% annual / 2% monthly / 4% PAYG); every enterprise feature free on every tier — never gated |
| Reduce AI costs | Lower cost per request for the same quality of answer | Route each request to the cheapest qualifying model; per-request cost on the x-nemo-request-cost header for exact attribution |
| Better performance | Fewer outages and consistent latency under load, automatically | Automatic provider fallback and routing strategies; per-key/team/org budgets and rate limits that contain blast radius |
| Faster AI deployment | Ship new models and features in days, not weeks | One OpenAI-compatible key for 78+ models — adopt a new provider with a config change, not an integration project |
Comparison reflects NemoRouter capabilities verified June 2026. SOC 2 Type II is in progress; AWS Bedrock is shipping next.
The reason this table sells where a feature list doesn't: each row starts in the language of the person signing off. Finance reads the first column. Engineering validates the third. Nobody has to translate "OpenAI-compatible endpoint" into "we'll ship faster" — the mapping is already done.
Summary
The business case for an LLM gateway is not "it has these features" — it's that one endpoint in front of every provider turns four outcomes leadership already wants into something you can deliver and measure: save money, reduce per-request cost, hold performance under load, and ship new AI faster. Lead your internal pitch with those outcomes and let the capabilities be the proof. When you're ready to put numbers behind the first row, walk through the LLM gateway buyer's guide.