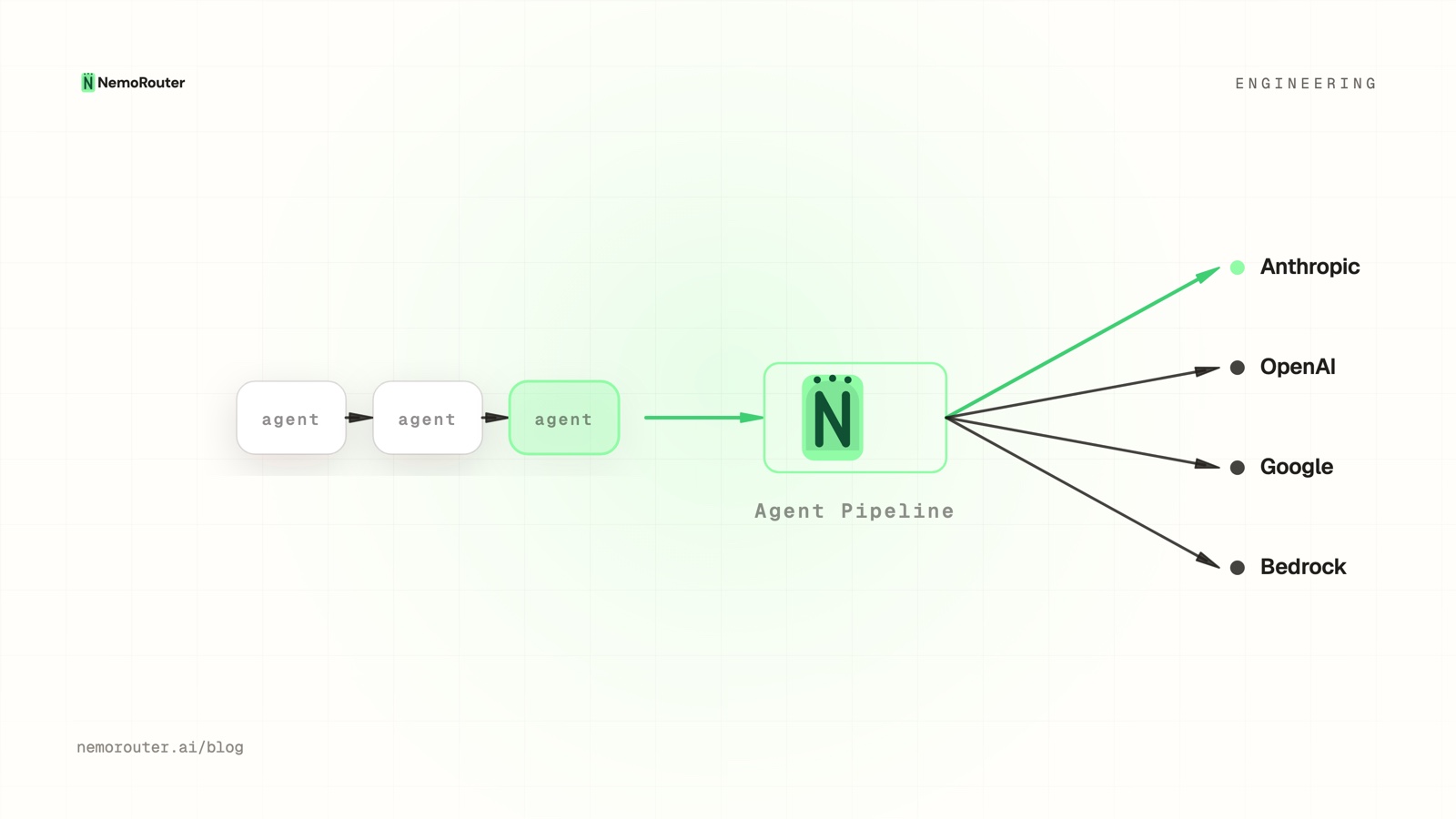
Agent frameworks put real pressure on LLM infrastructure. A single user request might trigger a planner call, three tool-use calls, two critic evaluations, and a final synthesis — each with different latency, cost, and capability requirements. Routing all of them through a single hardcoded model leaves performance and cost on the table.
This guide covers production routing patterns for multi-step agent pipelines: how to match models to tasks, handle mid-chain failures, and track cost per agent run.
The Core Problem: One Pipeline, Many Workloads
A typical ReAct-style agent pipeline looks like this:
User query
│
▼
Plan step (decide what tools to call)
│
▼
Tool execution loop:
├─ Tool call 1: web search
├─ Tool call 2: code execution
└─ Tool call 3: database lookup
│
▼
Synthesize (combine results into final answer)Each step has a different optimal model:
| Step | What It Needs | Best Model Choice |
|---|---|---|
| Planning | Reasoning, structured output | Frontier model (o3, claude-3-7-sonnet) |
| Tool selection | Speed, JSON accuracy | Fast mid-tier (gpt-4o-mini, haiku) |
| Synthesis | Quality, long context | Frontier or mid-tier depending on complexity |
| Critic/eval | Structured comparison | Mid-tier with good instruction following |
Sending every step to the same frontier model is the most common mistake in agent infrastructure. It inflates cost by 3-5x and adds latency where it is not needed.
How to Structure Routing with a Managed Gateway
With NemoRouter, every call uses the same endpoint regardless of model:
import openai
# One client, any model
client = openai.OpenAI(
api_key="sk-nemo-your-key",
base_url="https://api.nemorouter.ai/v1"
)You pass the model name per call. The gateway handles provider routing, authentication, and cost tracking transparently.
Routing by Task Type
The cleanest pattern is to define model assignments in one place and reference them throughout the agent:
from dataclasses import dataclass
from enum import Enum
class AgentTask(Enum):
PLAN = "plan"
TOOL_SELECT = "tool_select"
SYNTHESIZE = "synthesize"
CRITIQUE = "critique"
# Change routing in one place, not scattered across agent code
TASK_MODELS = {
AgentTask.PLAN: "o3-mini", # Strong reasoning for planning
AgentTask.TOOL_SELECT: "gpt-4o-mini", # Fast and accurate for JSON
AgentTask.SYNTHESIZE: "claude-3-5-sonnet-20241022", # Quality synthesis
AgentTask.CRITIQUE: "gpt-4o-mini", # Efficient for eval loops
}
def call_agent_step(task: AgentTask, messages: list, **kwargs) -> str:
model = TASK_MODELS[task]
response = client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
return response.choices[0].message.contentRouting by Context Size
Some steps receive large context (full conversation history, retrieved documents, tool outputs). Others only need a small prompt. Use this to save cost:
def select_model_for_context(messages: list, task: AgentTask) -> str:
# Estimate token count (rough: 4 chars ≈ 1 token)
estimated_tokens = sum(len(m["content"]) for m in messages) // 4
base_model = TASK_MODELS[task]
# Upgrade to a model with larger context window if needed
if estimated_tokens > 50_000:
context_upgrades = {
"gpt-4o-mini": "gpt-4o",
"claude-3-5-haiku-20241022": "claude-3-5-sonnet-20241022",
}
return context_upgrades.get(base_model, base_model)
return base_modelHandling Failures Mid-Chain
Agent pipelines fail in specific ways that differ from single-turn applications:
- Mid-chain provider outage — A provider goes down between steps 3 and 4 of a 7-step pipeline. Do you restart from scratch or resume from the last checkpoint?
- Rate limit during tool loop — The tool execution loop hits RPM limits on a fast model.
- Context overflow — The accumulated conversation grows past the model's context window mid-pipeline.
Provider Fallback
NemoRouter handles automatic fallback across providers when you configure a fallback chain for a model. But you can also implement explicit fallback in agent code for different failure types:
import asyncio
from openai import RateLimitError, APIError
FALLBACK_MODELS = {
"o3-mini": "claude-3-5-sonnet-20241022",
"gpt-4o": "claude-3-5-sonnet-20241022",
"gpt-4o-mini": "claude-3-5-haiku-20241022",
}
async def resilient_agent_step(
task: AgentTask,
messages: list,
retries: int = 2,
) -> str:
model = TASK_MODELS[task]
for attempt in range(retries + 1):
try:
response = await client.chat.completions.create(
model=model,
messages=messages,
)
return response.choices[0].message.content
except RateLimitError:
if attempt < retries:
# Back off and retry on the same model
await asyncio.sleep(2 ** attempt)
continue
raise
except APIError as e:
if attempt < retries and model in FALLBACK_MODELS:
# Switch provider on hard failure
model = FALLBACK_MODELS[model]
continue
raiseCheckpointing Long Pipelines
For pipelines longer than 3-4 steps, checkpoint intermediate state so failures do not require full restarts:
import json
import hashlib
class AgentCheckpoint:
def __init__(self, run_id: str):
self.run_id = run_id
self.steps: dict[str, str] = {}
def save(self, step_name: str, output: str) -> None:
self.steps[step_name] = output
# Persist to your store of choice (Redis, DB, file)
self._persist()
def load(self, step_name: str) -> str | None:
return self.steps.get(step_name)
def _persist(self) -> None:
# Implementation depends on your infrastructure
pass
async def run_agent_pipeline(query: str, run_id: str) -> str:
checkpoint = AgentCheckpoint(run_id)
# Step 1: Plan (resume if already done)
plan = checkpoint.load("plan")
if plan is None:
plan = await call_agent_step(
AgentTask.PLAN,
[{"role": "user", "content": query}]
)
checkpoint.save("plan", plan)
# Step 2: Tool calls (each checkpointed separately)
tool_results = checkpoint.load("tool_results")
if tool_results is None:
tool_results = await execute_tools(plan)
checkpoint.save("tool_results", tool_results)
# Step 3: Synthesize
final = await call_agent_step(
AgentTask.SYNTHESIZE,
build_synthesis_messages(query, plan, tool_results)
)
return finalCost Tracking Per Agent Run
The hardest part of agent cost attribution is that one user request generates many LLM calls across potentially different models and providers. You need to answer: "What did this agent run cost?"
Virtual Keys Per Agent Type
Create separate API keys for different agent roles. Each key gets its own spend tracking in the NemoRouter dashboard:
# Keys created via NemoRouter dashboard or API
# Each key maps to a role with its own budget and tracking
AGENT_KEYS = {
"orchestrator": "sk-nemo-orch-...",
"researcher": "sk-nemo-rsch-...",
"writer": "sk-nemo-writ-...",
"critic": "sk-nemo-crit-...",
}
def get_client_for_role(role: str) -> openai.OpenAI:
return openai.OpenAI(
api_key=AGENT_KEYS[role],
base_url="https://api.nemorouter.ai/v1"
)Now each agent role's cost shows up separately in your observability dashboard. You can see that the researcher agent costs $0.003 per run while the critic costs $0.0004 — and decide whether that ratio makes sense.
Run-Level Cost Attribution via User Field
For per-run tracking, use the user field to attach a run ID to every call. NemoRouter passes this through to the provider dashboard:
import uuid
def call_with_run_id(
task: AgentTask,
messages: list,
run_id: str,
) -> str:
response = client.chat.completions.create(
model=TASK_MODELS[task],
messages=messages,
user=f"agent-run:{run_id}", # Shows in provider dashboards
)
return response.choices[0].message.content
# Usage
run_id = str(uuid.uuid4())
plan = call_with_run_id(AgentTask.PLAN, messages, run_id)
# All subsequent calls in this run use the same run_idReading Cost Per Step
NemoRouter reports the exact cost of each call back on its response, so you can accumulate cost across pipeline steps to get a per-run total:
class CostTracker:
def __init__(self):
self.total_cost: float = 0.0
self.step_costs: list[tuple[str, float]] = []
def record(self, step_name: str, cost: float) -> None:
self.total_cost += cost
self.step_costs.append((step_name, cost))
def report(self) -> dict:
return {
"total_usd": round(self.total_cost, 6),
"steps": [
{"step": name, "cost_usd": round(cost, 6)}
for name, cost in self.step_costs
],
}The same per-step costs also roll up automatically in the NemoRouter dashboard, so you can read per-run cost there without any instrumentation.
Budget Enforcement for Agents
Long-running or recursive agents can accumulate unexpected costs. Set hard limits at the key level to prevent runaway spend:
# Configure via NemoRouter dashboard: set max_budget on the agent's key
# The gateway enforces this — the agent cannot exceed it regardless of code bugs
# In agent code: handle budget exhaustion gracefully
from openai import AuthenticationError
async def safe_agent_step(task: AgentTask, messages: list) -> str | None:
try:
return await call_agent_step(task, messages)
except AuthenticationError as e:
if "budget" in str(e).lower() or "402" in str(e):
# Budget exhausted — log and return gracefully
print(f"Agent budget exhausted at step {task.value}")
return None
raisePractical Model Selection for 2026
Based on current provider capabilities and pricing, here is a starting point for agent routing:
| Task | Recommended Model | Why |
|---|---|---|
| Complex planning / reasoning | o3-mini or claude-3-7-sonnet | Strong chain-of-thought |
| Fast JSON / tool selection | gpt-4o-mini or haiku-3-5 | Low latency, accurate structured output |
| Long-context synthesis (>32k) | gemini-1.5-pro or claude-3-5-sonnet | Large context windows |
| Embedding / retrieval | text-embedding-3-small | Cost-effective for high-volume retrieval |
| Code generation | claude-3-5-sonnet or gpt-4o | Consistent code quality |
| Quick classification | gpt-4o-mini or haiku | Sub-100ms latency |
The right answer changes as providers release new models. Using a managed gateway means you update one config line instead of hunting through agent code.
Next Steps
- Set up separate virtual keys per agent role for granular cost tracking
- Configure per-key budgets to enforce spending limits on autonomous agents
- Use the observability dashboard to monitor cost per model across agent runs
- Read the multi-agent cost tracking guide for deeper cost attribution patterns