The hardest cost problem in AI is not knowing what a single API call costs — providers publish that. The hard problem is knowing what a business operation costs when it involves dozens of LLM calls across multiple agents, models, and providers.
"Our AI feature cost $0.03 last month per user" is useful. "We're not sure — somewhere between $0.001 and $0.50 depending on what the agent does" is a billing time bomb.
This guide covers the infrastructure and code patterns for tracking, attributing, and bounding LLM costs in multi-agent systems.
Why Agent Cost Tracking Is Different
Single-turn applications have predictable cost: one request, one response, one line item. Agent costs are non-deterministic by design:
- A researcher agent might call 2 tools or 12, depending on query complexity
- A recursive summarizer accumulates context that grows token counts on each pass
- Parallel agent architectures fire multiple LLM calls simultaneously
- A loop that should run 3 iterations hits an edge case and runs 50
Without explicit cost attribution, you discover the problem when the bill arrives.
The Three Layers of Cost Attribution
Effective attribution works at three granularities:
| Layer | Question | Mechanism |
|---|---|---|
| Role | Which agent type is expensive? | Virtual key per agent role |
| Run | What did this specific job cost? | user field per run ID |
| Step | Which pipeline step drives cost? | Per-call cost accumulation |
You want all three. Role-level tells you where to optimize. Run-level tells you when a specific job went wrong. Step-level tells you exactly which operation to fix.
Layer 1: Virtual Keys Per Agent Role
Create a separate NemoRouter API key for each logical agent role in your system. Each key has its own spend dashboard, budget limit, and rate limit.
Dashboard view after setup:
sk-nemo-orchestrator $12.40 / 30 days
sk-nemo-researcher $89.20 / 30 days ← this is the expensive one
sk-nemo-writer $8.60 / 30 days
sk-nemo-critic $3.10 / 30 days
sk-nemo-embeddings $1.80 / 30 daysIn code, route each agent type to its key:
import os
from openai import AsyncOpenAI
# Keys from environment — never hardcode
ROLE_CLIENTS = {
"orchestrator": AsyncOpenAI(
api_key=os.environ["NEMO_KEY_ORCHESTRATOR"],
base_url="https://api.nemorouter.ai/v1",
),
"researcher": AsyncOpenAI(
api_key=os.environ["NEMO_KEY_RESEARCHER"],
base_url="https://api.nemorouter.ai/v1",
),
"writer": AsyncOpenAI(
api_key=os.environ["NEMO_KEY_WRITER"],
base_url="https://api.nemorouter.ai/v1",
),
"critic": AsyncOpenAI(
api_key=os.environ["NEMO_KEY_CRITIC"],
base_url="https://api.nemorouter.ai/v1",
),
}
def get_client(role: str) -> AsyncOpenAI:
if role not in ROLE_CLIENTS:
raise ValueError(f"Unknown agent role: {role}. Configure a key first.")
return ROLE_CLIENTS[role]This gives you immediate spend visibility per role without changing how agents call LLMs. The gateway tracks it automatically.
Layer 2: Run ID via the User Field
Each unique agent invocation should carry a run ID. Attach it to every LLM call via the user parameter:
import uuid
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class AgentContext:
"""Carries run-level metadata through the entire pipeline."""
run_id: str = field(default_factory=lambda: str(uuid.uuid4()))
job_id: Optional[str] = None # External job/task ID from your system
user_id: Optional[str] = None # End user (if applicable)
total_cost_usd: float = 0.0
@property
def user_tag(self) -> str:
"""Formatted user field passed to every LLM call."""
parts = [f"run:{self.run_id[:8]}"]
if self.job_id:
parts.append(f"job:{self.job_id}")
if self.user_id:
parts.append(f"user:{self.user_id}")
return "|".join(parts)
async def llm_call(
ctx: AgentContext,
role: str,
model: str,
messages: list,
**kwargs,
) -> tuple[str, float]:
"""
Make an LLM call with full cost attribution.
Returns (content, cost_usd).
"""
client = get_client(role)
response = await client.chat.completions.create(
model=model,
messages=messages,
user=ctx.user_tag,
**kwargs,
)
# NemoRouter reports the exact cost of the call back on the response
cost = extract_request_cost(response)
ctx.total_cost_usd += cost
return response.choices[0].message.content, costextract_request_cost reads the authoritative per-call cost NemoRouter returns — the gateway has already computed it, so your code never has to price tokens itself. The same per-run cost is also visible in the NemoRouter dashboard, attributed to the run via the user tag above, so you can reconcile your in-code total against the dashboard at any time.
Layer 3: Step-Level Cost Breakdown
For pipeline debugging, track cost at each step:
from typing import TypedDict
class StepCost(TypedDict):
step: str
model: str
role: str
cost_usd: float
tokens_in: int
tokens_out: int
class PipelineCostLedger:
"""Accumulates step costs for a single agent run."""
def __init__(self, run_id: str):
self.run_id = run_id
self._steps: list[StepCost] = []
def record(
self,
step: str,
role: str,
response,
) -> None:
# NemoRouter reports the call's exact cost on the response
cost = extract_request_cost(response)
usage = response.usage
self._steps.append({
"step": step,
"model": response.model,
"role": role,
"cost_usd": cost,
"tokens_in": usage.prompt_tokens if usage else 0,
"tokens_out": usage.completion_tokens if usage else 0,
})
@property
def total_cost(self) -> float:
return round(sum(s["cost_usd"] for s in self._steps), 8)
def most_expensive_step(self) -> StepCost | None:
if not self._steps:
return None
return max(self._steps, key=lambda s: s["cost_usd"])
def to_dict(self) -> dict:
return {
"run_id": self.run_id,
"total_usd": self.total_cost,
"steps": self._steps,
}Example Output
{
"run_id": "a3f2c1b4",
"total_usd": 0.004712,
"steps": [
{"step": "plan", "model": "o3-mini", "role": "orchestrator",
"cost_usd": 0.001200, "tokens_in": 450, "tokens_out": 380},
{"step": "research_query_1", "model": "gpt-4o-mini", "role": "researcher",
"cost_usd": 0.000180, "tokens_in": 320, "tokens_out": 150},
{"step": "research_query_2", "model": "gpt-4o-mini", "role": "researcher",
"cost_usd": 0.000240, "tokens_in": 420, "tokens_out": 200},
{"step": "synthesis", "model": "claude-3-5-sonnet-20241022", "role": "writer",
"cost_usd": 0.002800, "tokens_in": 2100, "tokens_out": 620},
{"step": "critique", "model": "gpt-4o-mini", "role": "critic",
"cost_usd": 0.000292, "tokens_in": 680, "tokens_out": 140}
]
}The synthesis step costs 59% of the total run. That tells you where to experiment with cheaper models.
Budget Enforcement
Budgets belong in the gateway, not application code. Application code has bugs. The gateway does not.
Key-Level Budgets
Set a max_budget on each agent key via the NemoRouter dashboard or API:
Role Budget Reset
orchestrator $50/month monthly
researcher $200/month monthly
writer $50/month monthly
critic $20/month monthlyWhen a key hits its budget, further calls return a 402 Payment Required error. Handle it in agent code:
from openai import OpenAIError
async def safe_llm_call(ctx: AgentContext, role: str, model: str, messages: list):
try:
content, cost = await llm_call(ctx, role, model, messages)
return content
except OpenAIError as e:
status = getattr(e, 'status_code', None)
if status == 402:
raise AgentBudgetExhausted(
f"Agent role '{role}' has exhausted its budget. "
f"Current run cost: ${ctx.total_cost_usd:.4f}"
)
raise
class AgentBudgetExhausted(RuntimeError):
"""Raised when an agent role hits its configured budget limit."""
passRun-Level Cost Guardrails
For long-running autonomous agents, add a cost guardrail at the run level:
class BudgetedAgentContext(AgentContext):
max_run_cost_usd: float = 0.50 # Default $0.50 per run
def check_budget(self) -> None:
if self.total_cost_usd >= self.max_run_cost_usd:
raise AgentBudgetExhausted(
f"Run budget of ${self.max_run_cost_usd:.2f} exceeded. "
f"Spent: ${self.total_cost_usd:.4f}"
)
# Check before each expensive step
async def guarded_llm_call(ctx: BudgetedAgentContext, role: str, model: str, messages: list):
ctx.check_budget()
return await safe_llm_call(ctx, role, model, messages)Parallel Agent Cost Tracking
When agents run in parallel, concurrent access to shared cost state requires thread/async safety:
import asyncio
from decimal import Decimal
class ConcurrentCostTracker:
"""Thread-safe cost accumulator for parallel agent runs."""
def __init__(self):
self._lock = asyncio.Lock()
self._cost = Decimal("0")
self._call_count = 0
async def record(self, cost_usd: float) -> None:
async with self._lock:
self._cost += Decimal(str(cost_usd))
self._call_count += 1
@property
def total_usd(self) -> float:
return float(self._cost)
@property
def call_count(self) -> int:
return self._call_count
# Running parallel researcher agents with shared cost tracking
async def run_parallel_researchers(queries: list[str], ctx: AgentContext) -> list[str]:
tracker = ConcurrentCostTracker()
async def research_one(query: str) -> str:
content, cost = await llm_call(ctx, "researcher", "gpt-4o-mini", [
{"role": "user", "content": query}
])
await tracker.record(cost)
return content
results = await asyncio.gather(*[research_one(q) for q in queries])
print(f"Parallel research: {len(queries)} queries, "
f"{tracker.call_count} calls, "
f"${tracker.total_usd:.4f} total")
return list(results)Practical Cost Benchmarks
After running these patterns in production, here are representative cost ranges for common agent architectures (April 2026 pricing):
| Agent Type | Calls per Run | Typical Cost | Expensive Outlier |
|---|---|---|---|
| Simple Q&A with retrieval | 2-3 | $0.001-0.003 | $0.02 |
| ReAct 3-5 step pipeline | 5-8 | $0.005-0.020 | $0.15 |
| Multi-agent research + synthesis | 10-20 | $0.020-0.080 | $0.50 |
| Recursive document analyzer | variable | $0.010-0.200 | $2.00+ |
The outliers are why budget guardrails matter. An edge case that triggers 10x the normal calls turns a $0.020 operation into $0.200 or worse.
What to Monitor
Three metrics tell you if agent costs are under control:
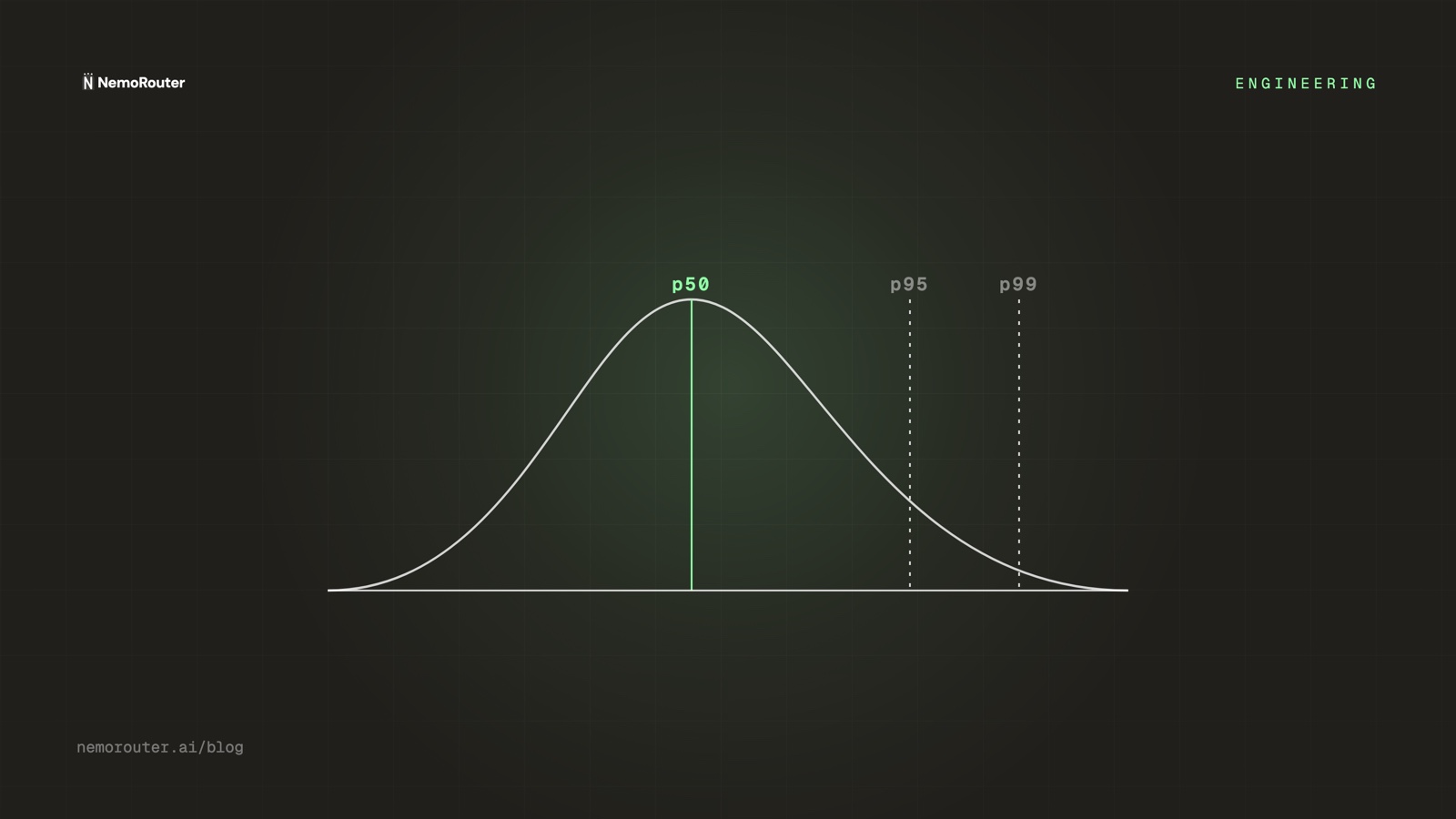
- P95 cost per run — The typical expensive run, not the average. Averages hide outliers.
- Cost per role as % of total — If one role jumps from 30% to 60%, something changed.
- Budget utilization rate — If keys consistently hit 80%+ of budget, resize the budget or optimize the agent.
All three are visible in the NemoRouter observability dashboard without additional instrumentation — the key-per-role setup does the work for you.
Summary
The full stack for multi-agent cost attribution:
- Virtual key per agent role → role-level spend visibility, enforced budgets
- Run ID in
userfield → per-run cost reconstruction in logs - Per-call cost accumulation → step-level cost breakdown
- Gateway-enforced budgets on each key → hard spending limits that agents cannot bypass
This gives you cost observability without building custom accounting infrastructure.