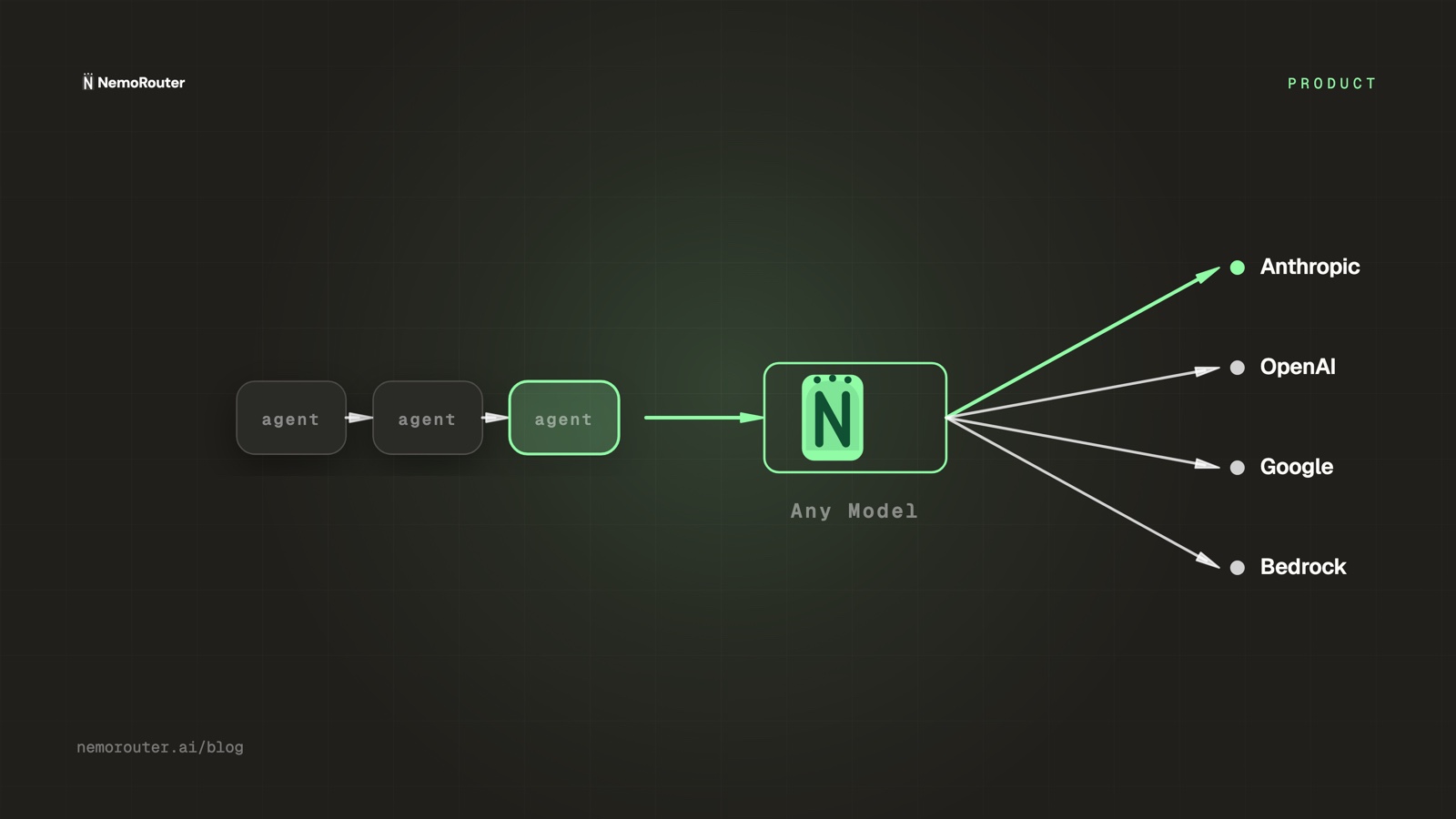
Agentic AI systems are fundamentally different from the chat applications that most LLM infrastructure was designed for. A chatbot sends one request and waits. An agent sends dozens — sometimes hundreds — of requests autonomously, branching based on tool results, retrying on failure, and calling multiple models for different subtasks.
This changes what you need from LLM infrastructure.
What Agents Need That Chatbots Don't
Multi-Model Access in a Single Pipeline
A well-designed agent pipeline uses different models for different tasks. The planning step needs strong reasoning. The tool-selection step needs fast JSON output. The synthesis step needs long context. The critique step needs consistent evaluation.
Hardcoding one model for all of this is the most common mistake in agent infrastructure. It means paying frontier-model prices for tasks where a fast, cheap model is actually better.
NemoRouter gives every call access to models from every major provider through the same endpoint:
import openai
client = openai.OpenAI(
api_key="sk-nemo-your-key",
base_url="https://api.nemorouter.ai/v1"
)
# Planning step — strong reasoning
plan = client.chat.completions.create(
model="o3-mini",
messages=[{"role": "user", "content": f"Plan how to answer: {query}"}]
)
# Tool selection — fast and cheap
tools = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": f"Choose tools for: {plan.choices[0].message.content}"}]
)
# Synthesis — quality output
answer = client.chat.completions.create(
model="claude-3-5-sonnet-20241022",
messages=[{"role": "user", "content": f"Synthesize results: {tool_results}"}]
)No provider configuration changes. No separate API keys to manage. One key routes to any model.
Rate Limits That Protect, Not Just Throttle
In single-turn applications, rate limits are annoying. In agent systems, they are safety controls. An agent with a bug that triggers an infinite loop will exhaust your provider rate limits — and run up your bill — before you notice.
NemoRouter enforces RPM and TPM limits at the key level. Set a per-key rate limit, and even a runaway agent cannot exceed it:
Key: sk-nemo-autonomous-researcher
RPM limit: 60
TPM limit: 100,000
Budget: $5.00/dayWhen the agent hits the limit, it gets a 429 response — which most frameworks interpret as a signal to back off. The damage is bounded.
Per-Agent Budget Enforcement
This is the feature that changes how teams think about autonomous agents. Instead of hoping your agent does not go off the rails, you configure a hard spending limit. When the key exhausts its budget, further calls return 402 Payment Required. The agent stops. No surprise bill.
Role Budget Period Alert At
orchestrator $20/day daily 80%
researcher $50/day daily 80%
writer $20/day daily 80%The gateway enforces this — not your application code. Application code has bugs. The gateway does not.
Observability Across the Full Pipeline
Agent pipelines fail in opaque ways. A run finishes with a bad result, and you need to answer: which step produced the error, which model was called, what did the prompt look like, and what did it cost?
NemoRouter's request log captures every call:
- Timestamp and latency
- Model used and provider routed to
- Input/output token counts
- Cost per call
- The API key alias that made the call
- HTTP status and any error detail
For agent pipelines, this turns debugging from guesswork into structured investigation. You filter by your agent's key, look at the failed run, and see exactly where it went wrong.
Provider Failover for Reliability
Autonomous agents often run unattended — overnight, in response to webhooks, as scheduled jobs. When a provider has an outage at 3am, you want the agent to automatically reroute, not fail silently until someone checks logs in the morning.
NemoRouter has built-in load balancing and failover. Configure a fallback chain, and routing degrades gracefully:
Fallback chain: fast-reasoning
Primary: o3-mini (OpenAI)
Fallback: claude-3-5-sonnet (Anthropic)
Fallback: gemini-1.5-pro (Google)Your agent code never changes. The gateway handles provider selection and failover automatically.
Guardrails on Every Agent Call
Agentic systems that process user input are guardrail targets. An agent that retrieves web content and summarizes it can be manipulated via prompt injection in the retrieved content. An agent with tool-calling capability can be pushed toward harmful tool use through adversarial inputs.
NemoRouter applies guardrails at the gateway layer — before the request reaches the LLM. This means guardrails run on every call in the pipeline, regardless of which step or which model:
# Guardrails apply automatically to every call through your org's key
# No extra code needed — configure once in the dashboard
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
# extra_body can override specific guardrail behavior per call
extra_body={
"nemo_guardrail_ids": ["pii-filter", "prompt-injection-detect"]
}
)This gives agent pipelines consistent safety enforcement without requiring each agent step to implement its own content checking.
The Virtual Key Architecture for Multi-Agent Systems
The pattern that makes this all work cleanly: one virtual key per logical agent role.
Your org's NemoRouter account
├── sk-nemo-orchestrator (RPM: 30, budget: $20/day)
├── sk-nemo-researcher (RPM: 120, budget: $80/day)
├── sk-nemo-writer (RPM: 30, budget: $20/day)
├── sk-nemo-critic (RPM: 60, budget: $10/day)
└── sk-nemo-embeddings (RPM: 500, budget: $5/day)Each key:
- Has its own rate limit tuned to that role's call patterns
- Has its own budget enforced by the gateway
- Shows up separately in usage analytics
- Can be rotated or revoked independently without affecting other agents
This structure makes agent infrastructure observable, bounded, and maintainable. When the researcher agent's spend jumps 3x, you see it immediately and investigate before it affects the rest of the system.
Integration with Agent Frameworks
NemoRouter uses an OpenAI-compatible API. Any framework that supports a custom base URL works without modification:
LangChain:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="claude-3-5-sonnet-20241022",
openai_api_key="sk-nemo-your-key",
openai_api_base="https://api.nemorouter.ai/v1",
)CrewAI:
from crewai import Agent, LLM
llm = LLM(
model="gpt-4o",
api_key="sk-nemo-your-key",
base_url="https://api.nemorouter.ai/v1",
)
researcher = Agent(
role="Research Analyst",
goal="Find accurate information",
llm=llm,
)AutoGen:
config_list = [{
"model": "o3-mini",
"api_key": "sk-nemo-your-key",
"base_url": "https://api.nemorouter.ai/v1",
}]
assistant = autogen.AssistantAgent(
name="assistant",
llm_config={"config_list": config_list},
)Any OpenAI-compatible client:
from openai import OpenAI
client = OpenAI(
api_key="sk-nemo-your-key",
base_url="https://api.nemorouter.ai/v1",
)The same key, the same gateway, the same cost tracking — regardless of which framework your agents use. Any agent framework that accepts a custom base URL and API key points at NemoRouter unchanged.
What You Get Without Building It
The alternative to a managed gateway is building it yourself: a proxy service that handles provider keys, rate limiting, cost tracking, and fallback routing. Teams do this. It takes weeks, accumulates technical debt, and needs to be maintained as the provider landscape changes.
NemoRouter provides this infrastructure as a managed service, which means:
- Provider keys are our problem — you never touch OpenAI, Anthropic, or Google keys
- Pricing updates automatically — when a provider changes pricing, cost tracking updates without a deploy
- New model access immediately — when a new model launches on any supported provider, it is available the next API call
- Compliance built in — SOC2 Type II and GDPR compliance at the gateway layer, not something you build into your agents
The infrastructure becomes invisible. Your team focuses on the agent logic that actually differentiates your product.
Getting Started
- Sign up at nemorouter.ai and create your organization
- Create one virtual key per agent role with appropriate rate limits and budgets
- Set your
base_urltohttps://api.nemorouter.ai/v1in your agent framework - Configure guardrails for your use case in the dashboard
- Use the observability dashboard to monitor cost and latency per agent role
The first agent run that hits a budget limit without crashing your application will make this worth it.