Every company building with AI today hits the same wall around week two. The prototype works. The model is impressive. And then someone asks: "How do we ship this to production?"
That question unlocks a cascade of infrastructure work nobody planned for. Which provider do we use? How do we manage API keys securely? What happens when the model goes down? Who tracks cost across teams? How do we enforce usage limits? Can we add a content filter?
We saw this pattern across every team we spoke to. Engineers were spending more time on AI infrastructure than on the product they were actually building. That is the problem NemoRouter is designed to solve.
The Problem Is Structural, Not Technical
The individual pieces are not hard. An API key is just a string. A billing webhook is a weekend project. Rate limiting is a few lines of middleware.
The problem is that every team solves each piece independently, in their own way, with their own edge cases, and then maintains that solution forever while the actual model landscape changes under them.
We calculated that a well-run team managing 4-5 AI providers directly spends roughly 15-20% of their AI engineering capacity on infrastructure that has nothing to do with their core product. For a 10-person engineering team, that is 1-2 engineers working full-time on problems that every other team is also solving in parallel.
That is the waste we wanted to eliminate.
Why We Focused on the Management Layer
Routing requests to the right provider is the well-understood part of the problem: provider authentication, request normalization, load balancing, and failover across 100+ providers. The hard, unglamorous part — the part every production team actually struggles with — is everything around the routing. So that's where we put our effort.
NemoRouter pairs reliable multi-provider routing with the enterprise management layer that production teams actually need:
- Multi-tenancy — proper tenant isolation enforced at the data layer, not application-layer checks that can be bypassed
- Credit-based billing — atomic reserve-and-settle transactions so teams can never accidentally overspend, regardless of concurrent load
- Guardrails — organization-level content safety that applies to every request without requiring teams to build their own moderation pipeline
- Prompt management — version-controlled templates with A/B testing, so prompt changes go through the same review process as code changes
- Observability — request logs, cost analytics, and alerting that give teams the visibility they would otherwise build themselves
The routing handles the horizontal complexity (many providers, many models). NemoRouter handles the vertical complexity (many teams, many users, compliance requirements, billing).
What We Got Right Early
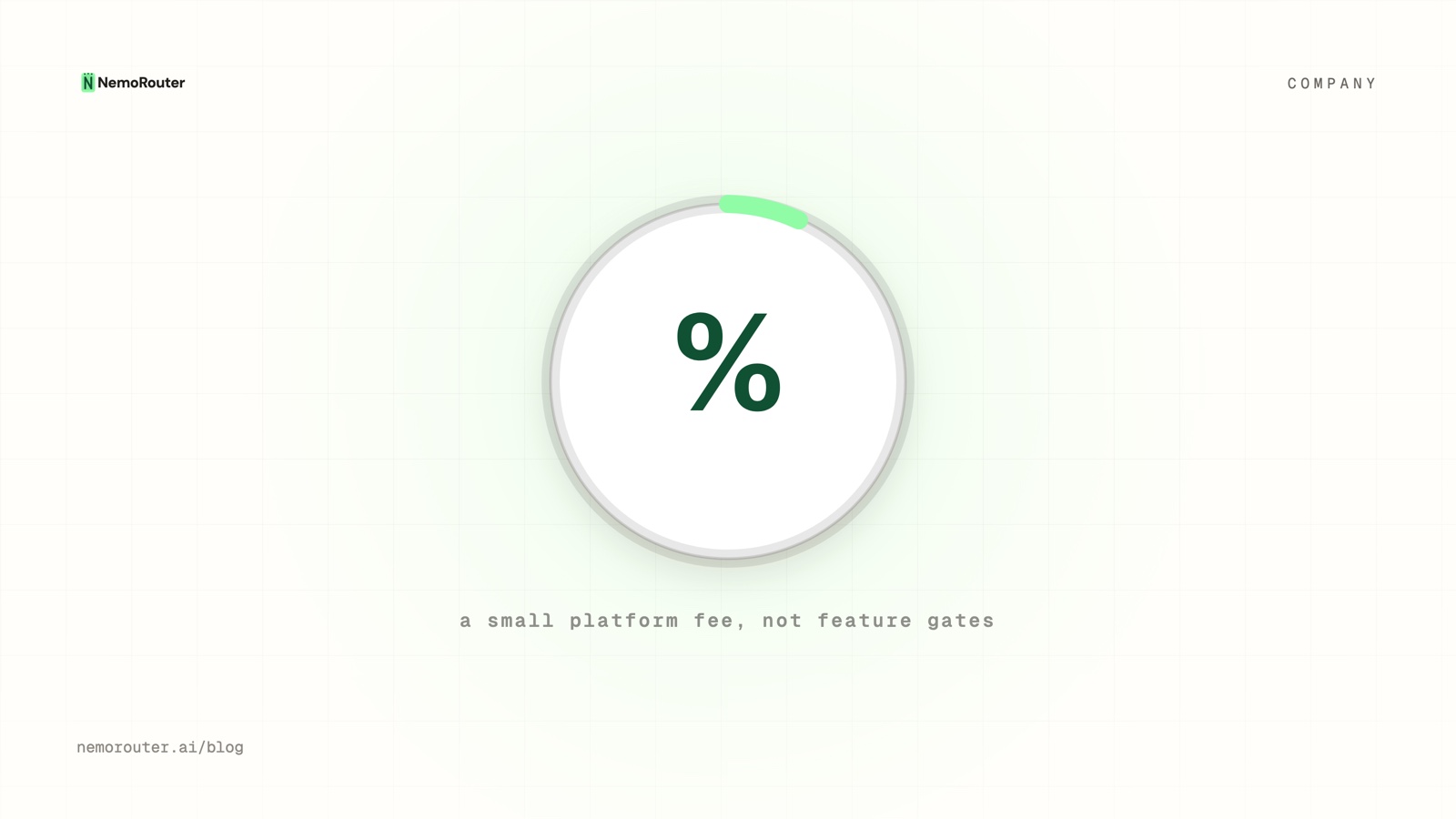
The decision we are most proud of is the platform fee model. We charge a percentage on top of credit purchases rather than gating features behind tier walls. This means every team gets access to every capability from day one.
Guardrails are not a paid add-on. Prompt templates are not an enterprise feature. Observability is not locked behind a dashboard upgrade.
Higher subscription tiers reduce the platform fee — 4% for pay-as-you-go, 2% at Tier 2, 0% at Tier 3. You pay less for infrastructure as you scale. But you never pay more to unlock functionality.
This came directly from customer feedback. The teams we spoke to were exhausted by infrastructure vendors who charged separately for every capability. They wanted one price, all features, no negotiation.
What We Got Wrong and Fixed
Our first version of the credit system had a race condition. Under concurrent load, two requests could both pass the balance check before either one updated the ledger, briefly allowing overspend. It was a small window — maybe a few seconds per key — but it was real.
We rewrote the billing layer around a reserve-and-settle pattern. When a request comes in, we immediately reserve the estimated cost from the balance. The actual cost is settled after the request completes, using the authoritative cost the provider reports for the call. Every failure path releases the reservation. The ledger is atomic.
We also underestimated how much teams care about a single organization per user. Our early design allowed users to switch between organizations, which created a whole class of ambiguous state problems: which org owns this key, which budget applies, which guardrails run? Simplifying to one org per user removed an entire category of bugs.
What Is Next
The model landscape is changing faster than any team can keep up with. New providers launch every few months. Existing providers ship new model families with different pricing, context windows, and capabilities. Teams should not need to think about any of this.
Our roadmap is oriented around making the infrastructure layer even more invisible: automated cost optimization based on performance benchmarks, predictive capacity provisioning for teams with consistent workloads, and deeper integration with the compliance workflows that enterprise security teams require.
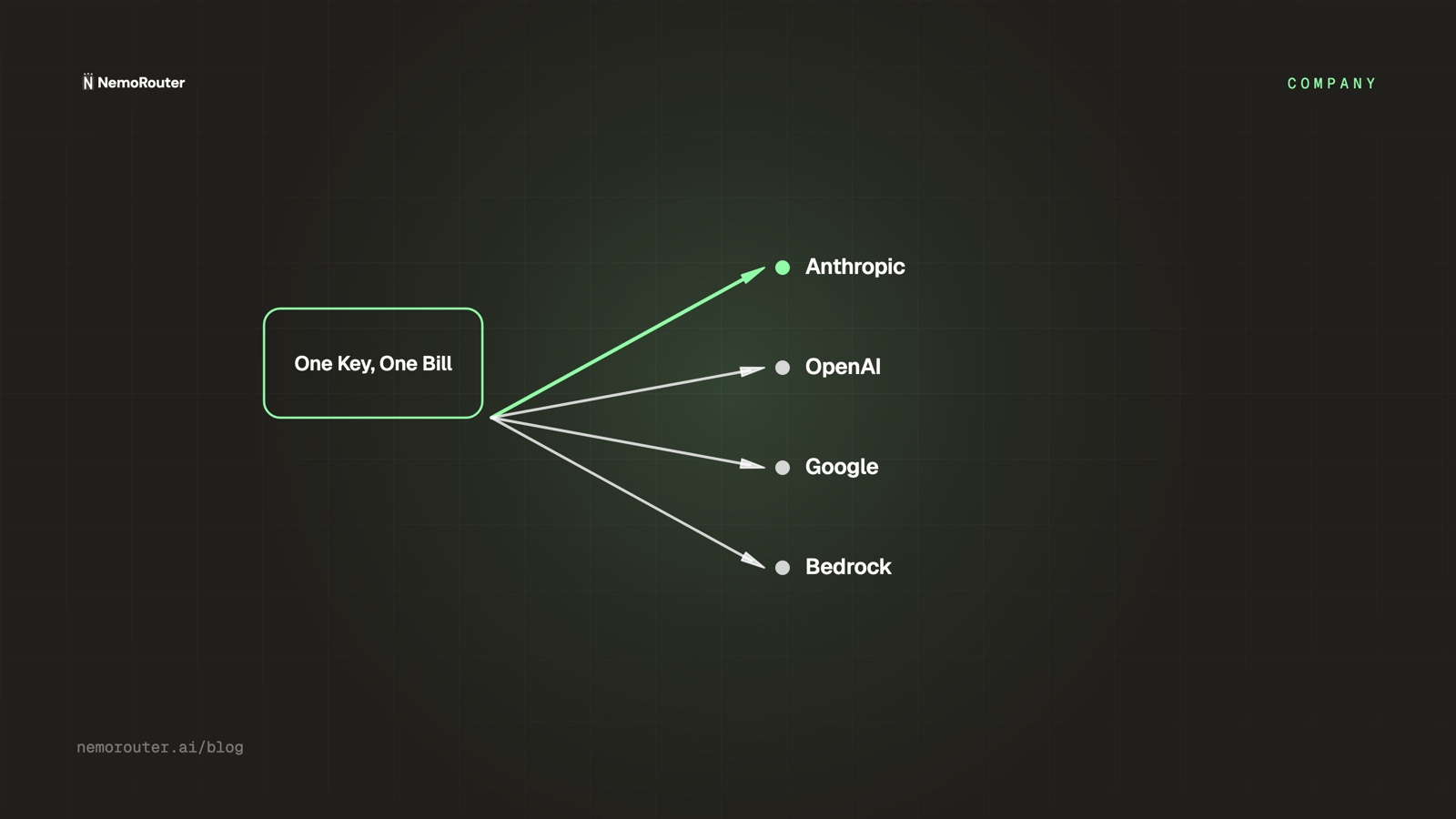
The goal has not changed since we started: one key, one bill, zero provider configuration. We just keep finding more ways to mean it.
We are hiring engineers who want to work on the infrastructure that makes AI teams faster. If this problem space interests you, reach out at careers@nemorouter.ai.